✅ 오늘 배운 것
여전히 배포 실패 이슈가 이어지고 있다! 이제 왜 로드밸런서의 헬스체크가 실패하는지는 알았는데, 어떻게 해야 성공시킬지를 잘 모르겠다.
생각해보면 지금 문제상황은 'python manage.py runserver'로 잘 돌아가던 서버의 명령어를 gunicorn, uvicorn을 사용하도록 바꾸기만 했을 뿐인데 배포가 안 되는 거였다. 그러면 이럴 경우에는 로컬호스트에서 서버를 띄워도 뭔가 확인 가능하지 않을까? 싶어서 로컬에서도 같은 gunicorn 명령어로 서버를 실행시켜 보았다.
로컬에서 Dockerfile의 명령어를 실행시키고, 로드밸런서에 등록한 엔드포인트로 도메인만 localhost로 바꿔서 요청을 보냈는데, 브라우저에는 응답이 잘 나오는데 로그에는 원하는 것처럼 200 반응이 뜨질 않았다. 그래서 AWS 로그를 볼 때도 이 서버가 요청을 제대로 받고 있는건지 모호했다.

알고보니 uvicorn에 'access-logfile' 이라는 커맨드를 추가해야 HTTP 로그에 대한 기록을 추가로 남길 수 있었다. 설정을 추가해 주니 요청에 대한 HTTP 로그도 볼 수 있었다. 이러면 이제 AWS에서 태스크가 실행될 때 로드밸런서가 해당 태스크 안의 컨테이너에 어떤 HTTP 요청을 보내고 있는지도 볼 수 있겠다.

그런데 좀 걸리는 점이 있다. 보통 8000번 포트에서 장고 서버가 실행되는 걸로 알고 있는데, 49735번 포트였다..! 혹시 로드밸런서는 계속 8000번 포트로 요청을 보내고 있는데 막상 gunicorn으로 시작된 서버는 다른 포트에서 시작하고 있었던 건 아닐까? 라는 생각도 들었다. 하지만 응답은 잘 오는데, 무슨 상황일까?
다행히 로그를 자세히 보니 8000번 포트에서 listening을 하고 있는 건 맞았다.

다음과 같이 명령어를 입력해주고 다시 develop 브랜치에 해당 내용을 올려보았다.
gunicorn onestep_be.asgi:application --timeout 300 -w 2 -k uvicorn.workers.UvicornWorker --log-level debug --access-logfile -
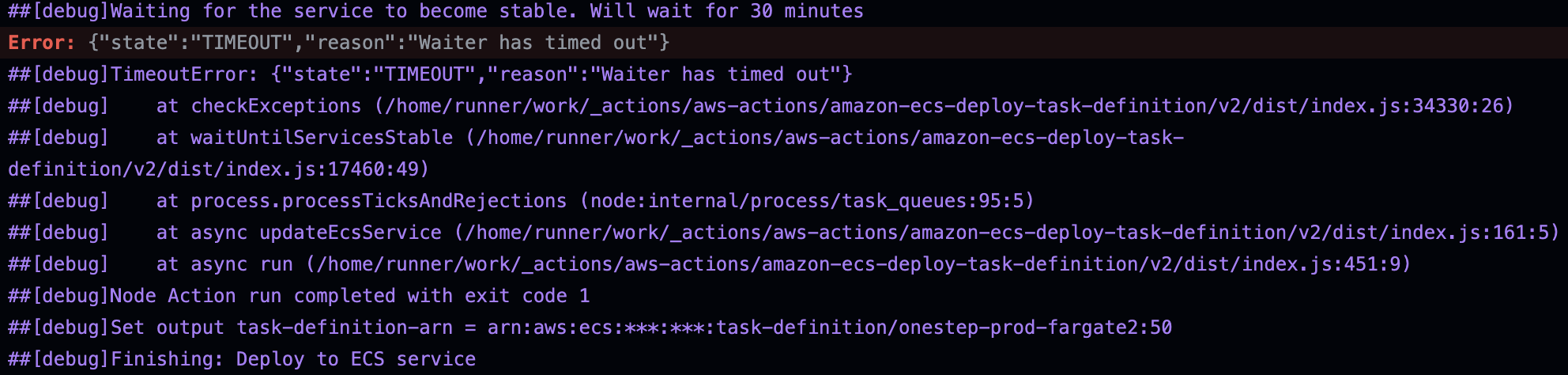
그런데 여전히 서버로 접속이 안 되었다. 워크플로우는 일단 서버가 성공적으로 배포가 되었으면, 그 이후에 헬스체크나 기타 설정에 상관 없이 성공하도록 wait-for-service-stability 설정을 바꿔 두었으니 성공하긴 했다. 문제는 로드밸런서의 헬스체크가 또 fail이 났다는 것이었다.
의심되는 부분은 과연 올바른 포트에 요청을 보내고 있는지였다. 왜냐하면 앞서 access-logfile 이라는 커맨드를 추가해서 HTTP 요청이 왔다면 로그가 남아있어야 하는데, 요청을 받았다는 로그 자체가 없었기 때문이다. 그래서 헬스체크가 fail이 된 것이라고 생각되었다.


GPT가 제시한 내용들을 봐도 감이 잘 잡히지 않았다. 제시한 내용들 중에는 '올바른 경로로 요청을 보내는지 확인해라', '태스크가 실패한 원인을 확인해라' 등의 내용이 있었는데, 이미 로컬에서 서버를 돌렸을 때는 올바른 경로로 200 응답을 잘 리턴하고 있었고, 태스크가 실패한 원인은 확인해봤더니 내가 아는 "Health check failed" 였기 때문이다.
어떤 단서라도 나오려나 싶어 CloudWatch에서 좀 더 자세한 실행 로그를 살펴보았다. 그랬더니 이런 문장이 눈에 띄었다.

찾아보니 이 설정은 "gunicorn이 어떤 IP의 요청으로부터 'X-forwarded-for' 이라는 헤더값을 신뢰할지" 를 결정하는 값이라고 했다. 그런가보다 하려다가, 'allow_ips' 라는 부분에서 혹시 이 gunicorn 서버가 외부 요청을 허용하지 않는 건 아닐까? 라는 의심이 들었다.

그 결과 'bind' 라는 부분에서 할당된 값이 '127.0.0.1:8000' 밖에 없다는 사실을 알았다. 즉 이 상황에서면 WAS 서버는 자기 자신과 같은 localhost가 아닌 외부에서 보낸 요청을 받지 않고 있다는 말이 되겠다. 로드밸런서야 당연히 해당 서버와는 또 다른 원격에서 실행되고 있기 때문에, 이거라면 접속이 안 되었던 이유가 설명이 되었다.

명령어를 다음과 같이, '--bind 0.0.0.0:8000' 부분을 추가해서 모든 외부 IP에서의 요청을 다 받도록 설정했다. 그 다음에 다시 워크플로우를 실행시켜 주었다.
gunicorn onestep_be.asgi:application --bind 0.0.0.0:8000 --timeout 300 -w 2 -k uvicorn.workers.UvicornWorker --log-level debug --access-logfile -
그랬더니 서버가 실행되었다!!

혹시나 싶어 ECS의 태스크가 최신 태스크 정의를 반영하고 있는지도 확인해봤다. 최신 태스크 정의를 반영하고 있었다! 그 말은 gunicorn, uvicorn을 통해서 django WAS가 정상적으로 동작하고 있다는 뜻이었다.
이제 진짜 진짜로 locust를 통해 부하 테스트를 해볼 수 있겠다.
그런데 또 뭔가 이상했다..! gunicorn으로 worker를 2개를 띄웠고, gunicorn으로 시작한 서버에서 로그가 잘 찍히고 있는 것도 확인했다. 그런데 테스트의 RPS(request per second) 지표가 영 시원찮았다. 테스트에서는 우선은 DB에 영향이 가지 않는 단순 조회 API만 사용하였다.
20명의 동시 접속자(유저)를 가정했을 때 RPS가 약 30 정도였다. 이 정도 수치면 예전과 거의 차이가 없었다.
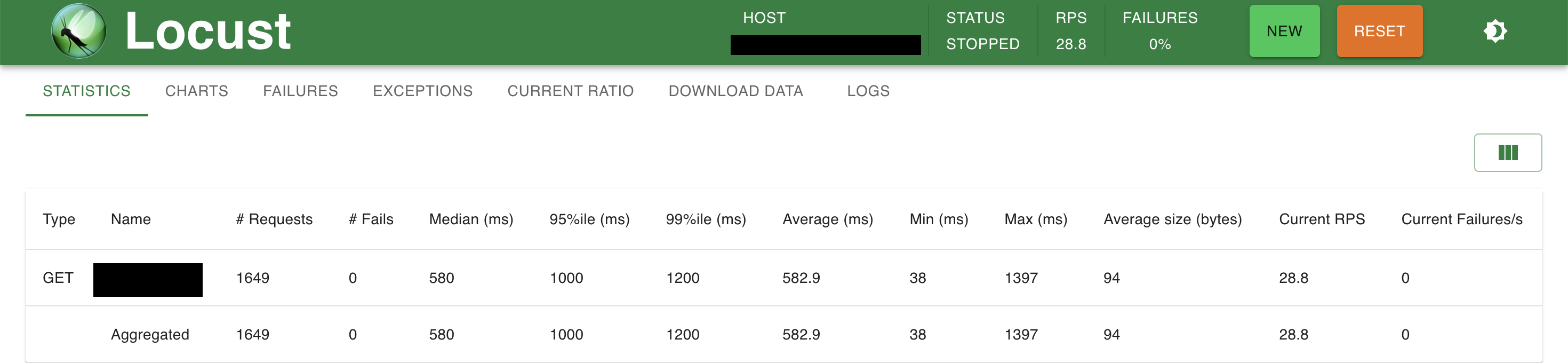
뭐지 싶어서 ECS 서비스의 CPU 사용률을 보았는데 CPU가 과로를 하다 못해 죽기 직전이었다. 식겁해서 돌리던 테스트를 일단 종료시켰다.

이런 경우는 어떻게 하면 좋을까? 애초에 우리 서버의 상태로는 RPS 1000이 무리였던 것일까? 아니면 위처럼 확인은 해 봤는데 설마 아직 gunicorn에서 2개의 worker가 서비스를 처리하고 있지는 않은 건가? 라는 생각도 들고... 일단 이 부분은 멘토님께 추가적인 조언을 구해보고 개선할 방법을 찾아봐야겠다. 일단은 아주 잠깐동안 보류해 보자!
그럼 다른 이슈를 해야 하나 싶어서 지라 이슈를 보니, SZ-243의 하위 이슈로 지금 당장 할 수 있는 것들이 남아있었다. 사실 여기에 1시간 정도를 쓴 터라 이제 다른 걸로 context switching을 하고 싶었는데 어림도 없다. 이거 먼저 해결하고 다른 것들을 하러 가보자.

우선은 매번 워크플로우 yaml 파일의 큰 용량을 차지했던 ECS의 '태스크 정의'용으로 매번 만들던 json 파일을 yaml 파일을 통해 만드는 부분을 개선해야 하겠다. 기존 방법 대신에, json 파일의 껍데기는 만들어 두자. 그리고 그 안의 환경변수와 관련된 내용은 동적으로 yaml 파일이 실행될 때 파이썬 스크립트를 통해 해당 파일 안에 넣어주도록 해 보자.
우선 위의 이슈는 계속 배포와 관련된 부분을 다루다보니 develop 브랜치에서 임시로 작업했었다. (사실 이게 바람직한 방법이 아닌 걸 알긴 하는데, 그럼 이렇게 사소한 변경을 하고 그 변경된 결과를 배포 서버에서 확인하고... 등의 작업을 할 때는 어떻게 해야 할까? 매번 PR 날리는 게 번거로워서 이 방법을 쓰고 있는데 그럼에도 PR을 매번 날리는 것이 옳은 방법인지 궁금하다.)
기존에는 'git pull origin develop'으로 매번 develop의 내용을 당겨 왔는데, 이제부터는 더 권장되는 방법인 git rebase를 사용해 보자. 다행히 큰 conflict 없이 develop 브랜치의 커밋들을 SZ-243 브랜치의 앞에 배치할 수 있었다.
git checkout SZ-243
git rebase develop

그런데 GPT가 제시한 방법은 로컬의 .env 파일에서 값을 가져와서 json 파일에 넣어주는 방식이었다. 그런데 이렇게 하면 모두가 이미 Github Secrets에 저장되어 있는 값을 굳이 .env 파일에 한번 더 저장해야 해서 번거롭다고 느껴졌다. 하지만 제시해 준 예제 코드를 보면서 어떻게 해야 할지 조금이나마 감은 잡았다.
우선 현재 yaml 파일에서 사용하고 있는 템플릿을 그대로 가져오자. 그리고 ecs-task.json 이라는 이름으로 프로젝트의 루트 디렉토리에 빈 템플릿용 json 파일을 만들어주었다.
그리고 render_ecs_task_definition.py 라는 파이썬 파일을 하나 만든다. 이때 로컬 .env 파일의 값은 가져올 수 없으므로, 파이썬 커맨드에서 필요한 Github Secrets 값을 인자로 받아 주어야 하겠다. 여기서 필요한 값들은 다음과 같았다:
AWS_ACCOUNT_ID, AWS_REGION, ECR_REPOSITORY_NAME, AWS_SECRET_NAME, AWS_ACCESS_KEY_ID, AWS_SECRET_ACCESS_KEY, AWS_SECRET_NAME_PROD.
다음과 같은 파일을 만들었다. 코드에서는 파일을 실행시킬 때 파라미터로 Github Secrets 값들 중 필요한 값을 넘겨받은 뒤, 그 값을 딕셔너리 형태로 변환한다. 이후 딕셔너리 형태의 키-값 맵을 이용해서 변환해야 하는 값(키)이 나오면 키-값 맵의 값으로 교체해주는 작업을 해 준다.
import argparse
import json
def replace_ecs_task_definition():
with open('ecs-task.json', 'r') as file:
task_definition = json.load(file)
parser = argparse.ArgumentParser()
parser.add_argument("--aws_account_id", type=str)
parser.add_argument("--aws_region", type=str)
parser.add_argument("--ecr_repository_name", type=str)
parser.add_argument("--aws_secret_name", type=str)
parser.add_argument("--aws_access_key_id", type=str)
parser.add_argument("--aws_secret_access_key", type=str)
parser.add_argument("--aws_secret_name_prod", type=str)
args = parser.parse_args()
global key_map
key_map = {
"AWS_ACCOUNT_ID": args.aws_account_id,
"AWS_REGION": args.aws_region,
"ECR_REPOSITORY_NAME": args.ecr_repository,
"AWS_SECRET_NAME": args.aws_secret_name,
"AWS_ACCESS_KEY_ID": args.aws_access_key_id,
"AWS_SECRET_ACCESS_KEY": args.aws_secret_access_key,
"AWS_SECRET_NAME_PROD": args.aws_secret_name_prod,
}
def render_ecs_task_definition(obj):
global args
if isinstance(obj, dict):
return {k: render_ecs_task_definition(v) for k, v in obj.items()}
elif isinstance(obj, list):
return [render_ecs_task_definition(v) for v in obj]
elif isinstance(obj, str) and obj.startswith("${") and obj.endswith("}"):
env_var = obj.strip()[9:-1] # remove ${secrets.} from string
return key_map.get(env_var)
return obj
task_definition = render_ecs_task_definition(task_definition)
with open('ecs-task.json', 'w') as file:
json.dump(task_definition, file, indent=2)
if __name__ == "__main__":
replace_ecs_task_definition()
나머지는 이따가 시간이 나면 더 처리해 보겠다.
✅ 궁금한 점
1. 8000번 포트에서 gunicorn으로 시작한 장고 WAS가 listening을 하고 있다고는 나왔는데 막상 로그에는 49735번 포트와 관련된 내용이 찍혔다. 이유가 궁금하다.
'개발 일기장 > SWM Onestep' 카테고리의 다른 글
| 20240825 TIL: 하위 투두 프롬프팅 시도하기 (0) | 2024.08.25 |
|---|---|
| 20240824 TIL: 파이썬 커맨드로 ECS 태스크 정의 json 파일에 동적으로 환경변수 값 넣기 & 서버 성능 향상 시도하기 (0) | 2024.08.24 |
| 20240822 TIL: uvicorn + gunicorn으로 서버 성능 향상하고 locust로 테스트하기 [진행중] (0) | 2024.08.22 |
| 20240821 TIL: 중간발표 준비 (0) | 2024.08.21 |
| 20240820 TIL: github workflow 최신 배포 반영 안되는 문제 임시로 해결 & 발표 준비 (0) | 2024.08.20 |