오늘은 멘토님과의 멘토링에서 어제 Locust로 API 서버 부하테스트를 했다는 부분을 말씀드리면서 피드백을 받았다. 당시 RPS(request per second)가 30-40 정도 나오고 있어서 괜찮은지 여쭤봤더니 멘토님께서는 1000 이상은 나오는 것이 안정적이라고 피드백을 주셨다! 그래서 왜 이렇게 RPS가 낮은지를 생각하고 있었는데, 지금 서버는 단일 서버로 돌아가고 있기 때문이었다. 따라서 uvicorn을 사용해서 서버를 여러 대 띄워야 RPS를 늘리고 서버의 부하를 줄일 수 있다고 하셨다.
gunicorn은 뭐고 왜 필요하지? 라는 의문이 들었는데 공식문서를 보니 바로 해결되었다. gunicorn은 unix 운영체제를 위한 python wsgi http 서버라고 한다. 그럼 WSGI가 뭐였지? 라는 의문이 또 드는데, 문서를 찾아보니 WSGI(Web Server Gateway Interface)는 웹 서버와 웹 어플리케이션이 어떻게 통신하고, 여러 개의 웹 어플리케이션이 하나의 요청을 처리하기 위해서 체인처럼 연결될 수 있는지를 정의한 인터페이스였다. 이제 gunicorn이 뭔지는 알았다.
그러면 uvicorn은 뭐고 왜 필요하지? 라는 의문이 든다. uvicorn은 파이썬 웹 서버에서 사용하기 위해 ASGI 인터페이스를 구현한 것이다. ASGI는 뭘까? 문서에는 ASGI(Asynchronous Server Gateway Interface)는 WSGI를 상속받은 또 다른 인터페이스이며, 비동기 요청을 처리하는 웹 서버와 웹 어플리케이션이 어떻게 통신하고, 비동기 요청을 처리하는 여러 개의 웹 어플리케이션들이 하나의 요청을 처리하기 위해서 체인처럼 연결될 수 있는지를 정의한 인터페이스였다. Implementation을 보니 uvicorn 말고도 daphne, granian, hypercorn 등 여러 신기한 라이브러리들이 있었다.
그런데 이렇게만 봐도 그래서 이 라이브러리들을 사용하는 게 서버를 여러 대로 늘리는 것과 무슨 상관이 있는지 사실 잘 와닿지 않았다.
알고보니 uvicorn은 별다른 설정이 없으면 단일 프로세스로 실행되는 ASGI 서버이다. 성능을 확장하는 방법은 여러 개의 uvicorn 프로세스(인스턴스)를 실행하여 각 프로세스가 독립적으로 요청을 처리하게 하는 것이다. 그러면 물론 당연히 하나의 서버에 실행 가능한 프로세스 수는 제한이 있겠지만, 적어도 늘어난 프로세스만큼 요청을 병렬적으로 처리하게 되어 서버의 성능이 향상되겠다고 이해했다.
그러면 gunicorn은 왜 필요한지 의아할 수도 있지만, 이렇게 여러 개의 uvicorn 프로세스를 통합해서 관리하도록 도와주는 것이 gunicorn이다. gunicorn에서는 워커(worker)라는 개념이 있다. 워커는 uvicorn 서버의 독립적인 인스턴스이다. 이쯤 되면 조금 헷갈린다. 아까는 여러 개의 uvicorn 프로세스를 통합해서 관리한다면서, 지금 얘기를 들으면 여러 개의 uvicorn 서버의 독립적인 인스턴스를 관리한다는 건가? 헷갈린다.
요점만 정리하자면 여기서 말하는 '워커'는 uvicorn 인스턴스가 맞았다. 그리고 uvicorn을 단독 실행할 때와 gunicorn과 같이 실행할 때의 차이점도 알 수 있었다. uvicorn을 단독 실행할 때도 기본적인 워커 관리 기능을 제공하지만 그 기능이 다소 제한적이다. 반면 gunicorn과 uvicorn을 같이 사용하면 워커 관리의 제어권을 gunicorn이 갖는 대신에 더 확장된 기능을 제공한다고 한다. 예를 들면 gunicorn과 같이 사용할 때는 워커를 모니터링하거나, 필요에 따라 재시작하는 등의 부가 기능이 있다고 한다.
gunicorn, uvicorn을 사용해서는 다음 명령어로 서버를 띄울 수 있다고 한다. 다만 우리 프로젝트에서는 개발, 프로덕션, 테스트의 세 가지 환경을 사용하고 있었기에 관련된 값도 넣어줘야 했다.
# 4개의 worker를 사용하는 경우
gunicorn onestep_be.asgi:application -w 4 -k uvicorn.workers.UvicornWorker
그리고 해당 문서를 보면 gunicorn에서 몇 개의 uvicorn 워커를 갖는 것이 적당한가? 라는 물음에 대한 답이 나와있다. 기본적으로 4개 ~ 12개 사이의 uvicorn 워커로 초당 수백 개에서 수천 개의 요청을 처리할 수 있다고 하며, 2*(core의 개수)+1개의 uvicorn 워커를 사용할 것을 권장하고 있었다. 왜 저런 식에 근거하였는지도 궁금하다.
프로젝트는 현재 ECS fargate 옵션으로 서버가 실행되고 있었는데, 몇 개의 uvicorn 워커가 필요한지를 알기 위해서는 서버에서 몇 개의 cpu core를 사용하고 있는지를 알아봐야 했다.
공식문서에서는 ECS fargate에서 cpu core의 수는 vCPU와 직접적으로 연관된다고 한다(왜인지는 모른다). 그리고 vCPU(virtualized CPU)의 수는 태스크 정의에서 정의된 "cpu"의 값에 따라 달라진다고 한다. ECS의 태스크 정의에서 확인하니 개발 서버의 경우 1vCPU(1024)를 사용하고 있었다.
그렇다면 공식으로 계산해보면 필요한 uvicorn 워커의 개수는 3개이다. 그러나 공식문서에서는 4개-12개 사이의 값을 권장하는 듯 보여서 4개로 설정해 주었다.
그리고 해당 값을 Dockerfile에 커맨드로 추가해 주었다.
# production 환경의 경우
CMD ["sh", "-c", "python manage.py migrate && DJANGO_SETTINGS_MODULE=onestep_be.setting.prod gunicorn onestep_be.asgi:application -w 4 -k uvicorn.workers.UvicornWorker"]
현재 문제가 발생한 코드는 이렇게 Api.js 파일에 정의된 함수들을 컴포넌트에서 가져와서 사용하는 방식으로 되어 있었다.
위의 프론트 이슈는 멘토님이 멘토링 시간 때 잠시 봐주시기로 했다. 이미 해당 이슈에 2시간을 넘게 쓴 상황이라, 더 이상의 시간을 쏟는 것보다 다른 이슈를 처리하는 것이 좋다고 판단했다. 그래서 백엔드로 Context Switching을 해 보기로 했다.
어제 작업하던 Locust로 API 부하 테스트하는 작업을 이어서 해 보려고 한다. 어제는 서버가 다운될까봐 쫄린 탓에 user를 1명으로 설정했지만, 이번에는 최대 유저 수를 100명으로 설정해 보았다. 그랬더니 다음과 같은 값을 얻었다.
초당 약 30-40개의 request를 처리할 수 있다면 어느 정도일까? 보통의 갓 런칭된 서비스라면 어느 정도의 RPS를 목표로 잡아야 할지, 그리고 RPS를 핵심으로 이 표를 보는 것이 맞을지도 헷갈린다.
그리고 지금은 단순 조회 API 하나만 테스트하고 있다. 그러나 실제 유저의 패턴은 훨씬 다양하고 분명 DB 조회뿐만 아니라 write를 하는 API도 불러올 것이기에, 이 API를 테스트 해봐야 겠다. 그러려면 테스트 환경에서 사용하는 DB는 테스트 DB로 별도 세팅이 필요하겠다.
GPT는 별도로 환경변수를 test DB를 가리키도록 설정해서 locust 스크립트를 돌리라고 말해주었다. 그런데 나는 그런 것보다 settings.py 환경파일에 test DB를 설정해놓으면 locust에서 해당 설정을 자동으로 참조하도록 해서 더 편하게 테스트를 하고 싶었다. 어떤 글에서도 나와 비슷한 사람을 발견했다.
일단은 별도의 테스트 환경에서 사용하기 위해서 RDS를 하나 더 만들어주자. 해당 값들을 AWS Secrets Manager에도 저장한 다음, settings 파일에도 테스트 DB와 관련된 설정을 하나 더 추가해줬다.
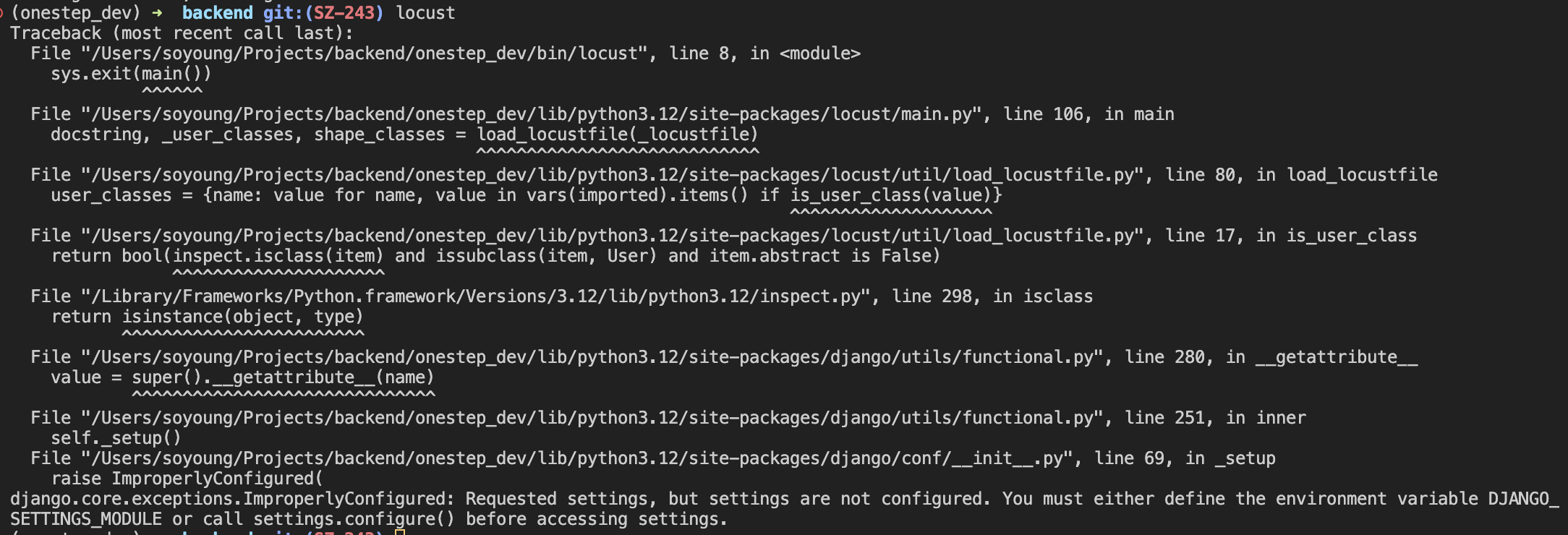
이유를 물어보았더니, 장고의 설정은 위에서 가져온 것처럼 django.conf.settings 모듈에서 관리된다. 그런데 이 모듈을 사용해서 설정 정보를 불러오기 전에 설정이 로드되지 않으면 ImproperlyConfigured 예외가 발생한다고 한다. 그렇기 때문에 django.conf.settings에서 불러올 환경이 어떤 기본값을 사용할지를 os.environ.setdefault() 함수를 통해 설정해 주어야 예외가 발생하지 않는다.
해당 에러를 해결하고 Locust의 로컬 서버를 띄웠다. 그랬더니 API에서 정상 반응을 리턴하지 않고 401, 500 에러가 떴다. 테스트 서버라서 유저 객체가 없었기 때문에 500 에러가 났고, 해당 API는 액세스토큰이 있는 유저에게만 401 응답을 리턴했기 때문이다.
이럴 경우엔 여러 가지 방법을 사용할 수 있어 보인다. GPT가 제시한 방법들 중 '사전에 발급된 액세스토큰 사용'이나 '프론트 URL을 통한 인증 절차 거치기'는 번거롭기도 하고 프론트가 웹이 아니라 앱이기 때문에 사용하기 어려웠다. 그래서 테스트 환경으로 실행할 시 인증을 건너뛰도록 설정해 봐야겠다. 테스트 환경에서는 모든 API에 대해서 인증을 잠시 우회할 것이므로, 특정 뷰에서만 동작하는 dispatch 메소드를 사용하는 대신 미들웨어를 사용하는 것이 더 간단하다고 판단했다.
우선 test.py라는 파일을 settings에 만들어 주고, 인증을 건너뛸지에 대한 여부를 저장하는 SKIP_AUTHENTICATION 변수를 settings.py에 정의했다. 기본값은 False였다. test.py 파일에서만 이 변수를 True로 세팅해 주었다. 이제 테스트 환경에서는 이 test.py에 설정된 환경을 가져오면 되겠다.
그리고 테스트 환경에서 서버가 실행될 경우 추가로 동작할 미들웨어 클래스도 정의해주었다.
from django.conf import settings
class SkipAuthMiddleware:
def __init__(self, get_response):
self.get_response = get_response
def __call__(self, request):
if settings.SKIP_AUTHENTICATION:
request.user = None
response = self.get_response(request)
return response
다만 해당 미들웨어 클래스는 테스트 환경에서만 동작해야 하므로, 테스트 환경 설정 파일에서만 아래와 같은 로직을 추가해서 MIDDLEWARE 변수의 맨 앞에 해당 미들웨어를 추가해 주었다. 미들웨어는 chain 구조로, 순서대로 사용자의 요청을 받고 그 반대 순서로 응답을 리턴하게 되어 있다. 따라서 맨 처음 요청을 받아 이를 승인해 주려면 MIDDLEWARE 변수 중 맨 앞에 해당 미들웨어를 넣어 주어야 하겠다.
# test.py
from onestep_be.settings import *
SKIP_AUTHENTICATION = True
if SKIP_AUTHENTICATION:
MIDDLEWARE.insert(0, "accounts.middleware.SkipAuthMiddleware")
그런데 고민이 생겼다. 지금 서버는 개발 서버와 프로덕션 서버 2개로 되어있다. 그래서 테스트 환경을 실행할 별도의 서버가 없다. 처음에는 기존 API URL에 '/test'만 붙인 테스트 전용 API를 만들어야 하나 고민도 되었다. 하지만 팀원과도 얘기해본 결과 그냥 별도의 테스트 환경이 하나 더 있으면 좋겠다는 결론이 나왔다.
그래서 develop 브랜치와 똑같은 코드를 배포하는 테스트 서버를 만들어야 하겠다. 즉 하나의 브랜치를 사용해서, 두 개의 서버를 다른 환경으로 띄워야 하는 상황이다.
처음에는 워크플로우 하나에 여러 개의 Job을 만들어서 해당 작업을 해야 하나, 아니면 별도의 워크플로우를 만들어서 작업해야 하나 고민했었다. 그러나 현재 ECR에서 도커 이미지에 태그로 달고 있는 값이 github.sha 값인데 이 값은 워크플로우가 가지는 고유한 값이므로, 두 개의 서버(개발 서버와 테스트 서버)가 모두 같은 도커 이미지를 참조해야 한다고 생각했다. 왜냐하면 어차피 두 서버는 모두 같은 브랜치의 내용을 반영할 건데 굳이 같은 하나의 이미지를 참조하면 될 일을 두 개의 다른 이미지를 각자 참조하게 만들 필요가 없기 때문이다.
...라고 생각했는데, 생각해보니 도커 이미지는 도커파일을 통해 만들어지는데, 두 환경에서 사용하는 도커파일이 달랐다. 그러므로 두 서버에서 사용하는 이미지들은 별개의 워크플로우를 사용해서 별도의 도커 이미지들로 만들어주는 것이 맞겠다. 그러므로 해당 작업은 별도로 하나의 워크플로우를 더 파서 진행하자.
그런데 또 고민이 생겼다.
그러면 하나의 서버가 더 필요한 것은 알겠다. 그런데 이를 별도의 클러스터를 하나 더 만들어서 진행할지, 아니면 같은 클러스터 안에서 서비스를 더 만들어서 진행할지, 그것도 아니면 같은 서비스 내에서 태스크를 하나 더 만들어서 진행할지를 모르겠다는 것이다. 멘토님은 정확히 잘 모르면 일단 해 보고 나중에 고치라는 방향으로 피드백을 주셨어서, 일단은 별도의 클러스터를 하나 만들어서 진행해 보려고 한다. 그러니까 현재 ECS에는 개발, 프로덕션, 테스트 이렇게 총 세 개의 클러스터가 있게 되겠다.
다시 멘토링 시간에는 프론트엔드로 Context Switching을 해 보았다. 애를 먹던 커스텀 훅 사용 문제가 있었는데, 멘토님의 피드백으로 도달한 결론은 커스텀 훅을 사용하는 대신 AsyncStorage로 토큰의 값을 저장소에서 가져오고, 토큰 값이 바뀔 때만 해당 값을 업데이트 해 주는 방법이었다. 이 방법도 크게 두 가지로 구현할 수 있었다.
첫 번째는 javascript class를 사용해서 Api 클래스를 구현하고, 그 안에 필드(멤버 변수)로 액세스 토큰값을 갖고 있는 방법이었다. 두 번째는 액세스 토큰값을 담은 전역변수를 사용해서 맨 처음엔 AsyncStorage에서 초기 액세스 토큰값을 가져온 뒤, 만약 값이 업데이트되면 해당 변수의 값을 바꿔주는 방법이었다. 두 방법 모두 동작했다.
그러나 첫 번째 방법이 좀 더 '객체지향적'이고 코드를 한 눈에 이해하기가 편하다고 판단했기에, 로직이 조금 더 복잡해져도 클래스를 통해 로직을 구현해보려고 한다.
그런데 이슈를 작업하고 블로그도 쓰다 보니 벌써 10시라서... 오늘은 여기까지만 하고 내일 위에서 언급한 부분들을 마저 마무리하자.
+ 이력서와 중간발표 대본 초안도!
✅ 궁금한 점 / 논의점 / 보완점
1. 테스트 DB로 사용하려는 RDS는 어떻게 관리해야 할까? 예를 들면 해당 RDS는 테스트 때만 요청을 처리하고 나머지는 IDLE한 상태로 있는데, 이럴 때는 그대로 두는 게 맞을지 아니면 테스트 때만 활성화하는 것이 맞을지 모르겠다.
2. LazyObject는 무엇일까? Lazy Loading이라는 말은 들어보았는데 추측해보면 이와 비슷한 맥락 같다.
3. (사실상 1번과 같은 고민) 테스트 서버를 하나 더 띄워두면 서버 유지 측면에서 뭔가 비용 등이 들 것 같아서, 이를 테스트 할 때만 켜 둬야 할지 고민이다. 그렇다고 매번 테스트를 할 때마다 테스트용 서버를 띄웠다 내렸다 하는 것도 번거로워 보이는데... 보통 기업이나 서비스에서는 어떻게 하는지도 궁금하다.
4. 테스트 서버를 어디다 띄워야 할지 고민이다. 별도의 클러스터? 개발 서버와 같은 클러스터에 있는 별도의 서비스? 아니면 개발 서버와 같은 서비스에 있는 별도의 태스크? 어떻게 하면 좋을지 고민이다. 아무래도 내가 ECS의 '클러스터', '서비스', '태스크'의 개념이 각각 정확히 무엇을 의미하는지를 잘 몰라서 이런 고민을 하는 것 같으니, 이 부분에 대한 정의도 찾아보자!
useCallback 콜백 함수로 감싼 handleLocalToken 함수가 undefined 값으로 나오고 있었다.
알고보니 useCallback으로 감싼 handleLocalToken 함수를 useHandleLocalToken 커스텀 훅보다 먼저 정의해서, 즉 useHandleLocalToken의 값이 undefined일 때 해당 값을 가져오려는 handleLocalToken 함수를 사용해서 에러가 난 것이었다. 이 문제는 useHandleLocalToken 함수를 handleLocalToken 콜백함수보다 먼저 정의해 주니 해결되었다.
이제는 로그인 화면까지는 잘 띄워졌다. 그런데 그 다음엔 구글로그인을 하면 다시 TodayView, 즉 투두 리스트 뷰를 보여줘야 하는데, 로그인 화면에서 넘어가지를 않았다. 이번에는 비슷한 문제로 'useVerifyToken'과 'useGoogleLogin'의 값이 undefined로 뜨는 것 같았다.
즉 useVerifyToken과 useGoogleLogin 함수(커스텀 훅)를 실행시켜야 하는데, 이 값이 제대로 인식되지 않아서 함수를 실행하지 못하고, 그러므로 로그인이 되지 않은 상태로 간주되니 투두 리스트 뷰로 넘어가지 못하는 상황으로 이해했다. 이 부분은 알고보니 import 구문에서 오류가 있어서, 이 부분을 수정하니 해결되었다.
문제는 여전히 구글로그인을 하고 나서 투데이 뷰로 넘어가지 않는다는 점이었다. 'Invalid hook call'이라는 부분으로 보아, 어제와 같이 커스텀 훅을 사용하는 과정에서 오류가 있는 것으로 보았다.
GPT에게 언어추론 문제를 내듯이 질문을 여러 차례 해 보았지만 마땅한 해답이 없었다. 즉 내가 리액트 훅을 잘못 사용하고 있는 게 거의 확실한데, 그게 어떤 지점인지를 모르는 게 문제였다.
에러 메시지에서 올려준 공식문서의 링크를 타고 들어가보았다. 요약하면 리액트 훅을 적재적소에 잘 사용하라는 것이고, 반복문이나 조건문 안에 사용할 수 없다는 것이었다. 혹시나 vscode에서 훅의 잘못된 사용을 캐치하지 못한 부분이 있을까 싶어 공식문서에서 추천한 플러그인도 설치해 주었다.
그렇게 삽질을 반복하던 중, 문득 어제 결론으로 내렸던 1번-2번-3번의 방식이 문법적인 오류를 내지는 않을지언정, 리액트 훅을 올바르게 사용하는 방식은 아닐 것 같다는 결론을 내렸다. 왜냐하면 애초에 useCallback 훅은 리렌더링 사이에서 함수를 계속 렌더링하는 것을 막는 용도였지 커스텀 훅의 사용과는 무관한 훅이었기 때문이다. 또한 임시로 만들어둔 'check local token'이라는 버튼을 누르면 토큰을 인증하는 verifyToken API를 호출하도록 되어 있고, 버튼을 누르면 onPress 함수로 useCallback()을 사용한 'handleLocalToken'이라는 함수를 호출하도록 되어 있다.
즉 이 버튼을 누르면 바로 handleLocalToken이라는 함수가 실행되어야 하는데, 여기서도 'Invalid hook call'이라는 오류가 떴다. 그러므로 애초에 이 방식이 올바른 방식이 아니라는 결론을 내렸다. 다시 원점으로 가 보자.
초심으로 돌아가 다시 던져보는 질문
그럴 듯한 방법을 찾았다. 요청을 처리하는 함수 자체를 훅으로 만든 다음, 그 함수를 커스텀 훅이나 컴포넌트에서 사용하도록 하는 방법이었다. 그런데 이걸 사용하는 방법에서도 문제가 있었다. 단순히 컴포넌트 최상단에서 훅을 사용하기만 하면 문제가 없는데, 이 훅을 컴포넌트에 있는 함수에서 사용하게 되면 '커스텀 훅은 일반 함수에서 사용할 수 없다'는 오류가 났다.
그러던 중 이런 오류를 발견했다.
몇번 더 삽질하면서 다음과 같은 질문을 해 보니, 커스텀 훅을 만들어서 사용할 때 내가 몰랐던 점에 대해서도 새롭게 알 수 있었다.
딱 이런 상황이었다. GPT 피셜, 리액트의 (커스텀) 훅은 컴포넌트나 다른 훅의 최상위에서 호출되어야 하기에 컴포넌트 내에서 커스텀 훅을 정의하고 그걸 Button의 콜백함수에서 호출하는 것 자체는 훅의 규칙을 위반한 것이라고 한다. 훅의 사용규칙을 설명하는 공식문서를 찾아보니 같은 내용이 있었다.
그렇다면 지금 작성된 코드를 다시 바꿔줘야 하겠다. 이쯤 되니 커스텀 훅에 대한 지식이 부족하다는 것이 많이 실감되었다... 커스텀 훅 관련 공식문서도 한번 읽어보자.
'Login' 컴포넌트 안에서 다음과 같은 'useHandleLocalToken' 이라는 커스텀 훅을 정의해두었다. 그리고 Button 컴포넌트의 onPress 함수로 해당 콜백함수가 호출되도록 하고 싶다.
무슨 문제인지 감이 잡히지 않아서 멘토님께도 도움을 요청드렸다. 멘토님께서는 useVerifyToken을 사용할 때 token만 파라미터로 넘기지 말고 onSuccess라는 콜백함수도 같이 넘기는 형태로 바꿔 보라고 말씀해주셨다. 처음에는 무슨 의미인지 잘 이해가 안 되었는데, GPT를 거친 다음 예제 코드를 보고서 이 피드백이 무슨 의미였는지 더 정확히 이해가 되었다.
onSuccess 함수(함수가 성공적으로 수행되었을 시 호출하려는 함수) 하나를 인자로 받았을 뿐인데, 이렇게 하면 비동기 작업을 더 유연하게 처리할 수 있겠다는 생각이 든다..! 다만 아직 내가 비동기 함수 호출이나 콜백 등을 깊게 이해한 상태는 아닌 것 같다. 왜 저렇게만 바뀌었는데도 비동기 작업을 유연하게 처리할 수 있는 것이고, 저 상황에서 어떻게 하면 저런 해결책을 떠올릴 수 있을까? 라는 궁금증이 생긴다.
그리고 이렇게 바뀌었어도 useHandleLocalToken 함수는 여전히 커스텀 훅 함수라서 Button 컴포넌트의 onPress 속성으로 전달할 수는 없다. 분명 멘토님이 주신 피드백에 실마리나 힌트가 있었을 것 같은데, 아직 나의 얕은 프론트 지식으론 한 번에 캐치할 수 없었던 것 같다..! 일단 수정된 코드가 담긴 링크를 전달드리고, 위 부분에 대해서 다시 여쭤봐야 할 것 같다.
프론트 이슈가 잠시 막혔으니 백엔드로 Context Switching을 해 보자. 사실 프론트가 막혀서 그렇지 백엔드도 할 게 정말 많다! 이번 스프린트 때 내가 맡은 이슈들 중 백엔드 건은 크게 두 가지이다.
1. 백엔드 API 서버 부하 테스트
2. EC2 AutoScaling 적용
당장 모레 멘토링이 있는데, 이때 전까지 프론트 막힌 부분과 이 두 가지의 이슈를 모두 해결하는 것을 목표로 잡아보자. 그래야 멘토링을 할 때 더 의미 있는 피드백을 받을 수 있을 것 같다. 그리고 그래야 남은 기간동안 예상치 못한 오류도 고치고 중간평가 준비도 할 수 있다...
암튼 백엔드 API 서버 부하 테스트 이슈부터 처리해 보자.
GPT와 구글링에서 찾은 유용한 블로그 글을 참고하며 진행해 보겠다. 우선 장고 API 서버에 부하 테스트를 하기 위해서는 "부하 테스트 도구"를 뭘로 할지를 결정해야 한다. 블로그와 GPT에서는 모두 Locust를 선택했는데, 이유는 테스트 스크립트를 파이썬으로 작성할 수 있다는 장점이 있어서였다. 그렇다면 Locust를 사용해서 테스트를 해 보자. 필요하면 공식문서와 깃허브도 참고해 보자.
시작하기 전에 궁금증이 생겼다. 예를 들면 투두를 생성하는 API에 대해 부하 테스트를 하면 투두가 생성된다. 그러면 그 데이터들은 어디에 저장되어야 할까? 테스트 DB에 저장되는 게 맞아 보이는데, 그러면 테스트 DB와 별도로 연결하는 작업이 필요하지 않을까? 이런 의문이 들었다.
그렇지만 아직 Locust가 '부하 테스트 도구'라는 것 외에는 아무것도 이해하지 못했으므로... 일단 시작해 보자. Locust는 서드파티 라이브러리이기 때문에 pip로 간단히 설치할 수 있다.
pip install locust
그리고 서버의 accounts 디렉토리 안에 locustfile.py 파일을 하나 만들어 두고, 가장 간단한 API를 테스트하는 로직을 작성해 보았다. 해당 API는 서버가 살아있는지 테스트용으로 만든 API로, 'hello world'라는 응답을 주는 것이 전부이다.
from locust import HttpUser, task
class HelloWorldUser(HttpUser):
@task
def hello_world(self):
self.client.get("/todos/todo?user_id=1")
공식문서의 QuickStart 부분을 보니 'locust' 명령어로 Locust 서버를 시작시키고(표현이 맞는지 모르겠다) localhost:8089로 접속하면 Locust의 WEB GUI를 볼 수 있다고 한다. 이때 주의할 점은 단일 파일로 부하 테스트를 시작하고 싶다면 파일의 이름을 locustfile.py로 하고 루트 디렉토리 바로 아래에 위치시켜야 라이브러리에서 인식할 수 있다.
웹 GUI도 잘 뜬다!! 너무 신기하다... 암튼!
이제 host를 개발서버 엔드포인트로 지정해 주고 요청을 보내 보았다. 사실 해당 필드값이 정확히 뭘 의미하는지, 얼마나 설정해야 유의미할지를 몰라서 그냥 둘다 1로 설정하고 테스트가 되는지만 보기로 했다. 그러니까 지금은 1명의 유저가 요청을 보내는 상황에 대한 테스트가 될 것이다.
GET으로 투두를 조회하는 API를 호출해 보았다. RPS는 Request Per Second로 서버가 현재 1초에 얼만큼의 요청을 처리하고 있는지를 나타내는 것이라고 이해했다. 요청의 95%는 110ms 이내에, 99%는 140ms 이내에 서버에서 응답이 리턴되는 것이라고 이해했다. 다만 이 경우는 유저에 맞는 투두 리스트를 단순 조회하는 API라서 더 복잡한 API는 별도의 테스트 로직을 작성해봐야 하겠다.
✅ 궁금한 점
1. 위에서 정의한 useHandleLocalToken 함수를 어떻게 Button의 onPress 이벤트가 발생했을 때 실행되도록 할 수 있을까?
2. RPS가 높을수록, 그리고 ms 값이 적을수록 서버가 요청을 잘 처리한다는 것은 알겠다. 우리 서비스의 경우는 어느 정도의 값을 목표로 하면 좋을까? 그리고 서버의 성능을 증가시키려면 어떤 작업이 필요할지도 궁금하다.
오늘의 목표는 스프링 프로젝트에서 기존 장고 서버에서 사용하고 있던 RDS와 연결하는 것이다. 사실 스프링 프로젝트는 정말 오랜만이고 거의 처음과도 다르지 않아서 어떻게 시작해야 할지 감이 오지 않았다.
모를 땐 GPT
기존에 스프링 프로젝트를 만들 때는 어떤 dependency가 필요할지 몰라서 최소한의 dependency인 Spring Web이랑 Lombok만 사용해서 만들었었다. 그런데 RDS랑 연결하기 위해선 DB Connection이 필요하고, 그러려면 Spring Data JPA와 MySQL Driver dependency가 추가로 필요했다(RDS가 MySQL로 되어있기 때문에 이게 필요하다).
스프링 프로젝트에 대한 dependency를 추가하는 방법은 예전에 몇 번 해봐서 알고 있었다. mavenRepository 공식 사이트에 들어가서, 원하는 dependency를 검색한 다음 해당되는 코드 라인을 build.gradle 파일에 추가해 주면 되겠다.
spring.datasource.url은 말 그대로 연결하려는 DB의 엔드포인트이다. 다행히 서비스에서는 RDS를 사용하고 있고 퍼블릭 IPv4 엔드포인트도 정의되어 있으므로, 이 값을 그대로 가져와주면 되겠다.
spring.datasource.username과 password는 DB에 접속하는 데 필요한 username과 password 값이다. 이 값은 장고 서버에서 정의하고 있는 DB_HOST와 DB_PASSWORD 값을 그대로 사용하면 되겠다.
spring.jpa.hibernate.ddl-auto 값은 예전에 보았는데 생각이 잘 안 나서 문서를 찾아보았다. 기본적으로 스프링 JPA에서는 서버를 재시작할 때 'create-drop' 모드, 즉 매번 DB 테이블을 생성하고 다시 drop하는 것이 기본값으로 되어 있다고 한다. 지금 이 프로젝트는 사이드 프로젝트이며, 장고 서버나 RDS에 어떠한 영향도 주면 안 된다. 그러므로 이 값은 none으로 설정했다.
값을 설정하는 것 자체는 문제가 없었는데, 문제는 이 파일을 그대로 깃허브에 올리면 안 된다는 점이었다. 그러면 application.properties 파일을 아예 올리지 말아야 할지, 아니면 해당 값들을 환경변수로 별도로 처리해야 할지 판단이 잘 서지 않았다.
GPT는 두 방법 모두 가능하다고 말해주었는데, 내가 판단하기엔 아무리 혼자 개발한다고 해도 application.properties 파일을 아예 올리지 않는 것은 설정 파일을 아예 별도로 로컬에서만 관리하는 식이므로 너무 1인 개발에만 적합한, 확장이 어려운 방식이라는 생각이 들었다. 그래서 환경변수로 별도로 처리해주기로 했다.
그러려면 java-dotenv라는 라이브러리가 별도로 필요했다. 정확히는 로컬에서 export 문으로 환경변수를 선언하면 해당 값을 별도의 라이브러리를 사용하지 않고도 application.properties 파일에서 사용할 수는 있었지만, 애초에 이 값은 프로젝트에서만 필요한 값인데 로컬에 별도로 정의하는 것은 맞지 않는다는 생각이 들었다.
참고로 해당 라이브러리는 mvnRepository에서 검색해도 안 나오고, 깃허브 레포에서 나온 순수 서드파티 라이브러리인 듯 하다. 공식적으로 지원하는 기능이 아닌 것은 아쉽지만 서드파티이면 어떤가. 오히려 이렇게라도 기능이 있다는 게 감사하다. 제발 오류가 없기를..!
아무튼 build.gradle에 해당 라인을 넣어두고 수정사항을 잘 반영한 뒤, 추가로 해 줘야 할 작업이 있다.
우선 src 디렉토리 바로 하위에 .env 파일을 추가하고, 불러오고 싶은 값들을 추가해 주자. 나의 경우는 다음과 같았다.
그리고 이렇게만 하면 .env 파일에서 변수값을 자동으로 가져올 수는 없다고 해서 또 추가적인 작업이 필요하다고 한다.
별도의 configuration 파일들을 모아두기 위해서 config 디렉토리를 만든 다음, 그 안에 DotenvConfig라는 Configuration 파일을 만들어 주었다. 이렇게 해야 .env 파일에 있는 환경변수 값들을 ${}으로 인식할 수 있는 것 같았다.
import io.github.cdimascio.dotenv.Dotenv;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class DotenvConfig {
@Bean
public Dotenv dotenv() {
return Dotenv.load();
}
}
필요한 설정은 다 되었겠거니 하고 서버를 시작해 보았는데 이런 오류가 났다. 아마도 .env 파일을 설정한 경로가 잘못된 것 같았다.
역시 공식문서를 잘 읽어봐야 하겠다... GPT도, 블로그 글도 결국엔 공식문서를 따라잡을 수 없나보다.
공식문서에 루트 디렉토리에 .env 파일을 생성하라고 딱 나와있었다. 바꿔서 생성하니 바로 서버가 떴다.
✅ 궁금한 점 / 느낀 점 / 보완할 점
1. 프로젝트를 빌드할 때 build.gradle 파일이 구체적으로 어떤 역할을 하는지와 그 원리가 궁금하다. 소스 코드를 찾아보자
2. 스프링에서 application.properties 파일을 어떻게 참조하는지도 궁금하다. 문서가 참 방대해서 다 읽을 수는 없겠는데, 필요한 기능을 그때그때 찾아보고 적어도 내가 쓴 코드가 무슨 의미인지 알려고 해 보자
4. spring.jpa.show-sql을 true로 하거나 false로 해야 하는 특별한 이유가 있을까? 단순히 어떤 SQL 쿼리가 실행되는지를 꼭 봐야 할 필요가 있는지 잘 이해되지 않아서 궁금하다
5. 기존에 잘 선언되어 있는 Django Model을 그대로 Spring Entity로 옮기고 싶다. 이걸 내가 소스 코드를 보면서 하나하나씩 바꾸는 방법도 있겠지만 과연 나와 비슷한 상황에 처한 사람이 한 명도 없었을까? 라는 생각이 든다. GPT와 티키타카를 좀 하면서 쉬운 방법이 있는지 찾아봐야겠다.
어제 언급했던 prod와 dev 개발환경을 제대로 분리해줘야 하겠다. 그리고 그러기 위해서는, 이전에 멘토님한테 코드리뷰를 받았을 때 피드백으로 언급되었던 부분도 같이 고쳐줘야 하겠다.
피드백으로 언급된 부분은 장고에서 환경변수를 주입하는 와중에 기본값을 'settings'가 아니라 'settings.dev' (직접 설정한 커스텀 파일의 경로)로 바꾼 부분이었다. 굳이 기본으로 주입되어 있는 값을 바꾸면, 사람들은 대부분 이 코드를 보지 않고 환경의 기본 설정은 settings로 되어 있겠거니 하는데 여기서 혼란을 줄 수 있다고 말씀하셨던 기억이 있다.
물론 위의 방법처럼 settings.dev로 아예 DJANGO_SETTINGS_MODULE의 값을 바꿔놓으면 python manage.py runserver 명령어에 별도의 변수를 넣어주지 않아도 기본값으로 개발환경이 실행된다는 장점이 있으나, 차라리 매번 runserver를 할 때마다 --settings=settings.dev 처럼 변수를 직접 넣어주더라도 피드백대로 하는 것이 더 좋다고 말씀하셨던 기억이 났다.
아무튼 그래서 기존에 prod와 dev 환경에서 겹치는 환경변수 값들을 넣어두었던 settings/base.py 파일을 기존의 위치인 settings.py로 다시 선언하고, settings.dev로 설정했던 DJANGO_SETTINGS_MODULE 환경변수의 값도 다시 초기값이었던 settings로 바꿔 설정해 두었다.
이제는 개발환경과 프로덕션 환경별로 별도의 도커파일을 만들어서, 각 워크플로우의 yaml 파일에서 develop 브랜치에 push가 들어올 때는 Dockerfile-dev 버전을, main 브랜치에 push가 들어올 때는 Dockerfile-prod 버전을 실행시켜주면 되겠다.
GPT가 알려준 방법들 중에, 환경별로 다른 Dockerfile을 사용하는 것이 제일 간단해 보여서 위의 방법을 사용해보려고 한다. 우선 두 개의 다른 도커 파일을 만들어 주자.
그리고 아래와 같은 과정을 추가해서 각 워크플로우의 프로세스가 작성되어 있는 yaml 파일에 Dockerfile의 경로를 지정하는 작업을 추가해주었다.
그런데 오류가 났다. 여기서 지정한 Dockerfile을 찾을 수 없다는 오류 같았다.
GPT는 docker build 명령어를 실행할 때 -f 옵션을 붙여서 명시적으로 도커파일 경로를 지정하는 방식을 추천해주었다. 앞서 위의 'Set Dockerfile Path' 단계에서 DOCKERFILE_PATH 라는 변수에 도커파일의 경로를 넣어 주었으니, 'env.DOCKERFILE_PATH'로 도커파일의 경로를 빼서 사용할 수 있다는 말로 이해했다.
이렇게 입력하니 깃헙 워크플로우는 약 7-8분만에 성공했다고 떴다. 그런데 예전의 전적이 있어서인지, 이게 과연 최신으로 반영된 상태가 맞을지 의심이 들었다. 그래서 현재 ECS 서비스의 태스크가 사용하고 있는 태스크 정의가 최신인지 확인해 보았다.
태스크는 28버전을 사용하고 있었는데 태스크 정의의 최신 버전은 29 버전이었다. 즉 태스크에서는 최신 버전을 사용하고 있지 않았다. 이런 경우 예전처럼 새 태스크 정의를 사용해서 태스크를 생성했다가 롤백했을 가능성이 있다.
서비스의 이벤트 로그를 보니 'rolling back'이라는 부분에서 ECS가 새 태스크 실행을 시도했다가 롤백했음을 알 수 있었다. 이전의 경험으로 봤을 때 아마도 서버를 실행했을 때 모종의 오류가 발생해서 그랬을 가능성이 높아서, CloudWatch의 최신 이벤트 로그들을 살펴보았다.
최신 이벤트 로그를 보니 역시나 Dockerfile에서 지정한 커맨드를 사용할 때 오류가 난 모양이었다.
이 오류는 dev 환경변수가 모여있는 파이썬 파일의 경로가 잘못 설정되어서 난 오류였다.
당시 settings.base 파일을 없애고 그 내용을 settings.py 파일로 옮겨주면서, 처음에 settings 디렉토리와 settings 파일이 한 곳에 있어서 오류가 났었다. 그래서 해당 settings 디렉토리의 이름을 setting으로 바꿔주었었다. 그런데 도커파일에서는 여전히 onestep_be.settings.dev 파일을 불러오고 있어서, settings라는 디렉토리가 없기에 난 에러였다.
이 부분을 수정하고 다시 워크플로우를 실행시키니, 워크플로우가 잘 성공하는 것은 물론이고 ECS 태스크에서도 가장 최신의 태스크 정의를 참조하고 있었다.
이제 프론트 부분에서 남은 이슈를 해결할 차례였다. 지금까지 프론트에서는 API 요청을 보낼 때 헤더를 만드는 함수를 metadata() 라는 이름으로 정의해서 따로 사용하고 있었다. 여기까지는 문제가 없었는데, 문제는 metadata 함수에서 파라미터로 액세스 토큰값을 받는다는 점이었다.
당시 액세스 토큰이 만료되면 자동으로 refresh API를 호출해서 새 액세스토큰 값을 받아오는 작업을 하고 있었는데, refresh API를 통해 새 액세스토큰 값을 받아오는 데는 성공했다. 문제는 그리고 요청을 다시 한 번 보낼 때, 기존의 만료된 액세스 토큰을 사용해서 요청을 보냈기 때문에 새 액세스토큰 값이 있어도 401 에러가 뜬다는 점이었다.
그래서 매번 AsyncStorage라는 비동기 저장소를 이용해서 해당 저장소에 저장해둔 액세스 토큰값을 가져오는 식으로 작업했었다. 하지만 프론트 멘토님께 여쭤보니 매 요청마다 AsyncStorage 저장소를 조회하는 것은 성능 면에서 Context API에 저장된 값을 조회하는 것과는 차이가 날 수밖에 없다고 말씀해주셨다.
왜냐하면 AsyncStorage 저장소 조회는 일종의 disk를 조회하는 작업이고, Context API 변수를 조회하는 것은 메모리 안의 값을 조회하는 작업이기 때문이다. 그래서 멘토님께서는 차라리 metadata 함수를 리액트 커스텀 훅으로 만들어서, Context API에 정의한 변수값을 사용할 수 있게 만드는 게 좋겠다고 말씀해주셨다.
여기서 AsyncStorage를 조회하는 코드를 빼고, Context를 조회하는 코드를 넣으면 된다. 그런데 그냥 냅다 코드를 넣어버리면 'useContext라는 리액트 훅은 리액트 커스텀 훅이나 컴포넌트 안에서만 사용할 수 있다'는 에러가 난다. 그러므로 metadata 함수를 리액트 커스텀 훅으로 만들어 줘야 하겠다.
리액트에서 어떤 함수를 커스텀 훅으로 만들고 싶다면, 함수 앞에 'use' 키워드를 붙여주면 리액트에서 해당 함수를 자동으로 커스텀 훅으로 인식한다. 즉 metadata를 useMetadata로 만들어 주었다.
그랬더니 에러가 난다. 이 에러는 metadata 함수를 훅으로 바꿔서 나는 에러인지는 모르겠어서 확인이 필요할 것 같다.
로그를 찍어보니 'Invalid hook call'이라는 부분에서 metadata 호출 부분 때문에 난 에러일 수도 있어 보인다.
GPT에게 물어보니 커스텀 훅을 제대로 정의하지 않았거나, 커스텀 훅을 올바르게 사용하지 않는 경우 이런 에러 메시지가 표시된다고 했다. 현재 useMetadata() 함수는 axios 안에서 호출되고 있어서, 이 부분이 잘못되지는 않았는지 GPT에게 다시 물어보았다.
GPT 피셜, axios 안에서 useMetadata라는 커스텀 훅을 호출하는 것은 잘못된 접근이라고 한다. 왜냐하면 axios는 컴포넌트도, 별도의 리액트 훅 함수도 아니기 때문이다... 그러려면 컴포넌트 안에서 useMetadata 훅을 사용해서 헤더 값을 받아온 뒤, 그 헤더 값을 사용해서 axios 요청을 보낼 때 사용해야 한다고 한다... 그런데 그러면 헤더 값에 꼭 최신 액세스 토큰값이 들어있으리라는 보장이 없어서 이 방법을 쓸 수는 없다.
그러면 또 방법이 있는 게 handleRequest()라는 요청을 보내고 간단하게 에러를 처리하는 함수를 또 커스텀 리액트 훅으로 만들어서 useHandleRequest()라는 함수를 정의하고, 그 함수를 또 리액트 컴포넌트나 리액트 커스텀 훅 안에서 호출하는... 그런 마트료시카 같은 방법도 있겠다. 그런데 쓰다보니 굳이 번거롭게 그래야 하나? 그럼 다른 사람들은 대체 어떻게 API 요청을 보내면서 그 안에서 커스텀 훅을 사용하나... 라는 의문도 들었다.
일단 물어보자
몇 번의 티키타카를 한 끝에 나름의 답을 얻었다.
우선 현재 사용하고 있는 Api 코드를 useApi라는 훅으로 만들 수 있겠다. 그리고 useApi라는 커스텀 훅 안에서 여러 기존에 사용하고 있던 함수들을 정의한 다음에, 그 함수들을 export 하는 방식으로 사용해볼 수 있겠다.
GPT가 준 예제 코드를 보면 다음과 같다.
import { useCallback } from 'react';
import axios from 'axios';
import { useMetadata } from './useMetadata'; // Assuming this is the path to your useMetadata hook
import { API_PATH } from './config';
const useApi = () => {
const { headers } = useMetadata();
const fetchTodos = useCallback(async (userId) => {
try {
const response = await axios.get(`${API_PATH.todos}?user_id=${userId}`, { headers });
return response.data;
} catch (error) {
// Handle error (similar to your handleRequest function)
console.error(error);
throw error;
}
}, [headers]);
// Similar wrappers for other Api functions
// addTodo, deleteTodo, etc.
return {
fetchTodos,
// other API functions here...
};
};
export default useApi;
그리고 컴포넌트 안에서 관련된 API를 호출하는 함수가 필요할 때는 다음과 같이 가져올 수 있겠다.
const { fetchTodos } = useApi();
즉 현재 구조인 Api 파일은 코드가 잘 나눠져 있으나 안에서 커스텀 훅을 사용하기는 불가능한 구조이기 때문에, 앞으로 useMetadata와 같은 훅을 이 안에서 제한 없이 사용하려면 코드를 변경해 줄 필요가 있겠다.
그럼 팀원들과 논의한 다음 코드를 변경해 보자. 팀원들도 이 방향이 좋을 것 같다고 해서 이 방법대로 가 보려고 한다. 이러려면 자잘하게 변경해줘야 하는 코드들이 꽤 있다.
야심차게 Api를 useApi라는 커스텀 훅으로 바꾸는 작업을 시작했으나, 이내 또 다른 난관에 봉착했다.
위에 GPT가 준 예시 코드처럼 useCallback이라는 리액트 훅 안에 원하는 함수를 넣었더니, 리액트 커스텀 훅은 콜백 함수(useCallback) 안에는 넣을 수 없다는 에러가 떴다. 그래서 콜백을 빼 보았더니 에러가 안 났다.
문서를 찾아보니, useCallback은 리렌더링 사이에서 함수를 캐싱할 수 있도록 해 주는 리액트 훅이었다. 새삼 useCallback이 뭔지도 잘 모르고 사용했구나 싶어 조금 반성이 되었다.
암튼 그렇게 했더니 또 다른 문제가 있었다. 사실 이 작업은 모두 "어떤 요청을 하더라도 최신의 액세스 토큰을 가지고 요청을 하는 것"이 목적이었다. 그러려면 결국은 요청이 처리되는 handleRequest()라는 함수에서 useMetadata()라는 커스텀 훅을 호출할 수 있어야 했다.
그렇다. 즉 handleRequest도 커스텀 훅으로 만들어야 한다는 뜻이었다. 그러면 useHandleRequest()를 정의해 주고, 그 useHandleRequest()라는 커스텀 훅 역시 커스텀 훅이나 컴포넌트 안에서만 사용될 수 있으므로 useHandleRequest()를 사용하는 모든 API 호출 로직에 있는 함수들을 다 훅으로 만들어준 뒤, 컴포넌트에서 그걸 호출하면 되겠다.
쓰다보니 이게 맞나 싶다. 그러나 Context 내부의 변수를 참고하려면 useMetadata라는 훅이 반드시 필요하고, 또 API 호출 단에서 가장 최신 값의 헤더를 얻으려면 useHandleRequest()라는 커스텀 훅 안에서 useMetadata라는 훅을 호출해야 한다. 그러려면 useHandleRequest를 사용하는 다른 함수들도 전부 커스텀 훅으로 만들어야 하겠다.
그리고 나중에 프론트 멘토님께 이 방향이 맞을지에 대해서도 피드백을 받아봐야 하겠다.
...라고 생각하고 있었는데, useApi와 그 안에 선언된 커스텀 훅 함수들을 다른 곳에서 사용하는 과정에서 에러가 났다.
에러가 난 이유는, 컴포넌트 안에 있는 훅 함수가 아닌 함수에서 커스텀 훅 함수를 호출하기 때문에 에러가 났다. 그런데 그 호출하는 함수를 또 마냥 커스텀 훅으로 만들 수는 없었다. 왜냐하면 해당 함수를 useEffect()라는 리액트 훅에서 호출하고 있었는데, 리액트 기본 훅에서는 커스텀 훅 함수를 호출할 수 없었기 때문이다(이것도 왜인지 모르겠다...).
아무튼 그래서 찾은 결론은 다음과 같다.
1. 커스텀 훅 함수를 호출하는 또 다른 커스텀 훅 함수를 컴포넌트 내에 정의한다.
2. 해당 1번의 함수를 useCallback() 콜백 함수를 통해 호출하는 '그냥 함수'를 만든다.
3. useEffect() 등에 함수를 사용해야 할 경우 2번 함수를 사용한다.
그런데 문제는 왜 이 방법으로 하면 되는지를 모르겠다는 것이다. 아마도 지금은 리액트 훅 함수에 대한 기본적인 원리를 잘 이해하지 못해서 그런 것 같다. 어쨌든 이 방법이 잘 되긴 하니, 일단 이렇게 해 보고 차차 원리를 알아보자.
✅ 궁금한 점 및 논의/보완점
1. git rebase의 원리가 궁금하다. git pull과 뭐가 다를까?
2. context API 안에 선언된 변수를 커스텀 훅이나 컴포넌트 안에서만 쓸 수밖에 없는 이유가 궁금하다
3. ECS에서 현재 github workflow로 인해 생성된 새 태스크로 기존 태스크를 교체하는 과정에서 무중단 배포가 일어나는 게 맞을까?
4. 팀원이 expo의 SecureStore라는 라이브러리를 추천해주었다. 이게 다른 localStorage나 AsyncStorage와는 또 어떻게 다른 것인지 궁금하다
5. 왜 리액트 기본 훅 함수 안에서는 리액트 커스텀 훅을 사용할 수 없도록 해 두었을까
6. tanstack-query의 useQuery를 사용할 때 queryFn 변수 값으로 리액트 커스텀 훅 함수를 넣는 방법이 없을까? 지금은 임시방편으로 useApi와 Api를 같이 만들어서 사용하고 있지만 이렇게 하면 useQuery()를 사용해서 데이터를 가져오는 도중 액세스 토큰이 만료가 되면 에러처리를 할 방법이 없다. 그래서 이건 결국 임시방편이고... tanstack-query에서 방법을 찾아서 제대로 처리해야 할 것 같다.
어제의 작업을 통해서 배포 시간은 평균 20분에서 8분으로 약 10분 이상 단축되었다. 그러나 여전히 개발 서버가 develop 브랜치의 최신 내용을 반영하지 못하고 있었다. 이쯤 되면 혹시 develop 브랜치의 내용이 ECR에 안 반영되는 것이 아닌가 하는 의심도 들었는데, ECS 클러스터>서비스>태스크의 컨테이너 정보를 확인해보니 의문이 풀렸다.
왜인지는 모르겠지만, 컨테이너는 ECR 레포지토리의 latest 태그가 붙은 이미지를 참조하고 있었다(참조한다는 표현이 맞는지 모르겠다).
그렇다면 다시 yaml 파일을 봐야 하겠다. 사실 지금은 yaml 파일을 이리저리 건드려보는 중이라서... 뭘 해도 어떤 근거로 무조건 develop 브랜치와 잘 연동될거다!는 확신은 없다. 그래도 바꿀 점이 또 있나 찾아본 결과, docker build 구문에서 기존에는 커맨드에 ECR 레포지토리의 값만 넣어주었는데, 막상 전체 주소는 이와 좀 다른 것 같았다. 그래서 이 값을 바꿔주었다.
그리고 해당 아래의 값도 바꿔주었다.
기존에 raw string으로 task definition을 입력해서 ecs-task-def.json 파일에 넣어주는데, 막상 해당 task-definition 필드를 보니 환경변수 값으로 되어있었다. 그보다는 방금 입력한 태스크 정의값이 들어있는 파일을 넣어 주는 것이 인식이 잘 될 것 같아서 값을 바꿔주었다.
여전히 되지 않는다...(develop 브랜치와 개발 서버의 내용이 다르다) 다시 처음으로 돌아가서 GPT에게 질문을 해 보자.
+ 검색하다가 yaml 파일의 설정이 어떻게 되어있는지를 알려주는 공식문서를 찾았다! 그동안 이게 뭔지 잘 모르면서 입력했던 설정값이 다 여기서 정의된 값들이었다.
[공식문서]와 [파일]을 주고 GPT에게 문제를 내보았다
GPT는 크게 설정은 수정할 부분이 없으나, ECS 태스크 정의를 렌더링하는 과정에서 revision과 taskDefinitionArn 필드를 빼라고 알려주었다. 이유는 family 필드를 정의하면 이미 ECS에서 태스크 정의를 인식할 수 있고, revision 필드의 경우 수동으로 지정하기보다는 자동으로 (아마도 1씩 revision 값이 증가하도록) 지정하는 것이 원칙인 것 같았다.
이렇게 또 yaml 파일을 변경하고 커밋을 올려보았는데, 아직도 개발 서버와 브랜치의 내용이 달랐다. 그리고 위에서와 같이 서비스가 어떤 태스크 정의를 사용하고 있는지도 보았는데, 또 이전 태스크 정의를 사용하고 있었다. 그래서 이번에는 강제로 서비스에서 사용하고 있는 태스크 정의를 바꿔주는 커맨드를 사용해 보았다.
이 작업도 실패해서, 이번에는 ECS 클러스터>서비스에 들어가서 '서비스 업데이트'를 누르고 사용하는 태스크 정의를 최신 버전(현재는 27)으로 바꿔주었다.
그런데 문득 이렇게 태스크 정의를 세세히 입력해 주었는데 '태스크 정의'에는 막상 등록한 json 파일 내용들이 잘 들어있고, 서비스에서 사용하는 태스크 정의는 정작 업데이트 되지 않았다는 점이 의아했다. 어쩌면 깃헙 워크플로우의 세부 단계에서 태스크 정의 렌더링(Render Task Definition)은 잘 되었는데 그 다음 작업(태스크 정의 등록 또는 ECS 서비스 배포)에서 무언가 오류가 나서 전체 작업이 롤백 되었을 가능성도 있겠다.
실제로 ECS 클러스터>서비스의 '이벤트' 탭에서 찍힌 기록을 확인해보니 'roll back'이라는 문구가 보였다. ECS에서 새 태스크 정의를 통해 새 태스크를 만들고 이를 서비스와 연결하려다가 만약 실패하면 이 작업을 다시 롤백하는 것으로 보였다.
그래서 롤백하기 전 시도했던 이벤트를 CloudWatch의 로그 그룹에서 찾아서, 구체적인 로그를 찾아보았다. 그랬더니 문제는 예상 외로 다른 곳에서 발생하고 있었다.
이 부분은 aws.py라는 직접 만든 파이썬 파일에서 AWS Secrets Manager를 통해 환경변수들을 불러오는 부분이었다. 여기서 에러가 나고 있어서 이후에 ECS 클러스터에서 태스크가 정상적으로 실행되지 않았고, 그래서 다시 서비스가 기존 태스크를 사용하도록 롤백했을 가능성이 있다.
문제를 찾아보기 위해서 AWS Secrets Manager와 develop 브랜치의 aws.py 파일을 확인해 보았다. 추측되는 원인 중 하나는, prod 값에 따라서 해당 파일에서 "AWS_SECRET_NAME_PROD" 라는 변수를 조회하게 될 수 있는데 이 값이 로컬 환경변수에는 있고 태스크를 정의하면서 선언해준 환경변수에는 없다는 것이었다.
로컬의 .env 파일태스크 정의 파일에서 주입한 환경변수들
그래서 태스크 정의 파일에다 하나의 환경변수를 더 넣어 주었다. 그리고 다시 로그를 봐야겠다.
연결 성공했다! 즉 원인은 환경변수가 주입되지 않아서 runserver 명령어 실행 시 에러가 났고, 그것 때문에 다시 새 태스크 정의로 만든 태스크가 롤백이 되었던 것이다.
위의 투두를 추천해주는 API가 계속 반영이 안 되어서 애를 먹었는데, 이제는 API 목록에 잘 뜬다.
다만 한 가지 걱정되는 점은, 원래는 /swagger URL로 접속하면 django swagger 라이브러리에 의해 모든 API들을 편하게 볼 수 있는 페이지가 나오는데, 이게 더 이상 나오지 않는다는 것이다. (/swagger URL로 접속하면 오류는 안 나지만 빈 페이지가 나온다) 짚이는 원인으로는 settings에 설정한 DEBUG=False 값이 걸리는데, 원래 DEBUG 모드가 아니면 해당 창이 안 나오는 게 정상적인 것인지, 아니면 어떻게 잘 커스텀해서 DEBUG 모드가 아니어도 API를 모아보는 페이지를 보이게 할 수는 없는지도 알아봐야겠다.
이제 이걸 참고해서 main 브랜치의 setting도 위와 같이 바꿔주면 되겠다.
main 브랜치의 workflow 파일을 바꾸려다 깨달은 점인데, develop 브랜치에서 프로덕션 서버 세팅을 사용하고 있었다... 왜인지 찾아보니 이전에 Dockerfile에서 프로덕션 환경을 주입하는 명령어를 써 놓고는 까먹은 것이었다.
그래서 이 환경을 분리하는 작업도 해 줘야 하겠다.
✅ 기타 정보들
1. 관련 문서를 보니 yml 파일에서 github.sha 값을 사용하길래, 이게 커밋을 고유한 값으로 나타내는 것이라고만 알고 있었다. 그런데 SHA는 해싱 알고리즘이었다. 해싱과 암호화의 차이가 뭔가 싶어서 문서를 찾아보니, 해싱은 단방향이고 암호화는 양방향이라고 한다. 즉 커밋 해시값은 커밋의 내용(정확히 어떤 내용인지는 모르겠다. git diff 명령어에서 나오는 커밋에서 변경된 부분을 입력하는 것일 수도 있다고 추측해본다)을 SHA 해싱 알고리즘을 통해 해시 값으로 바꿔서 커밋을 고유하게 나타내기 위해서 사용한다고 이해했다.
2. 참고할 수 있는 좋은 문서를 찾았다! 다음에 또 유사한 문제가 생길 경우 얘를 참고해야겠다.
✅ 궁금한 점
1. github settings에서 secrets와 env의 차이가 궁금하다.
2. ECS에서 태스크가 실패했을 경우 롤백을 하는 방법이나 그 원리가 궁금하다.
3. yaml 파일에서 커맨드로 브랜치에 따라 각기 다른 변수값을 주입하지 않고, 설정에서 GUI로 미리 브랜치별 환경변수를 설정하고 싶다.
오늘은 어제 진행 중이던 이슈를 계속 진행해 볼 예정이다. 더불어 workflow의 진행이 20분동안 걸리는 것도 문제인 것 같아서, 멘토님께 여쭤보니 ECS에서 health check를 하는 과정에서 시간이 길게 걸릴 가능성이 있다고 말씀해주셨다.
즉 서버 배포 관련해서 해결해야 할 이슈는 긴급도 순으로 정리하면 다음과 같겠다.
1. yaml 파일을 계속 수정하면서 develop 브랜치의 최신 내용이 개발서버에 반영되도록 하기
2. 로드밸런서의 health check에서 시간이 약 20분 정도 걸리는 문제 해결
3. github workflow에 pytest 및 runserver 테스트하는 로직 추가
4. 서버 성능 테스트 해 보기
오늘은 이 중에서 1번과, 가능하다면 2번까지 해 보는 것을 목표로 하면 좋을 것 같다. 특히 2번도 꽤 급한 게, 1번이 되는지를 빨리 확인하고 싶은데 계속 몇 분씩 기다려야 해서... 이것도 사실상 1번만큼 급한 이슈인 것 같다. 그냥 1-2번은 가리지 않고 같이 해결하면 될 것 같다.
답답
github workflow의 로그를 보니 AWS ECS 클러스터>서비스>이벤트의 로그를 보라고 말해주어서, 이 로그를 보면 뭔가 힌트를 얻을 수 있을 것 같아서 찾아봤다.
로그는 은근 친절하다
로그를 보면 (내 추측이지만) 태스크를 시작하고(has started 1 tasks), EC2에서 지정한 타겟 그룹(여기서는 onestep_dev)에 타깃을 등록하고(registered 1 targets in target-group), 해당 태스크에 대해서 커넥션을 차단(draining connections)하는 패턴의 반복인 것 같다.
그리고 이 패턴은 5분마다 반복된다. 왜일까? 이것은 설정값과 관련이 있어 보인다. 사실 이전에 기본값으로 로드밸런서의 헬스체크 간격이 10초로 되어있는데, 이걸 300초로 바꿨었다. 지금 생각해보면 왜 그랬나 싶지만, 그때는 그것 때문에 로드밸런서에서 서버에 10초마다 계속 요청을 보낸다고 생각했었고, 그게 너무 서버에 쓸데없는 요청을 계속 날리는 게 아닌가 싶어서 그 값을 딱 5분인 300초로 설정해 놓았었다... 쓰다보니 이게 원인일 가능성이 높겠다.
그렇다면 어서 바꿔보자. EC2>대상 그룹에 들어가서 해당 대상 그룹의 기존 헬스체크 기준을 보니 2번 연속 성공이고, 2번 연속 실패하면 fail로 간주하며, 각 요청의 간격은 300초(...)로 되어 있었다. 그래서 이 요청의 값을 2번 연속 성공, 4번 연속 실패하면 fail로 간주하며, 요각 요청에서 응답이 올 때까지는 5초간 기다리고, 각 요청의 간격은 10초로 설정해 주었다.
로드밸런서의 설정을 해 주었어도 여전히 태스크가 fail이 나면 다시 실행되는 작업들이 5분 간격으로 진행되고 있었다. 그래서 정확히 뭘 해야할진 모르겠지만 로드밸런서의 타깃 그룹 설정 외에도 다른 것들을 해 주어야 할 것 같다. 마침 멘토님께서 참고하라고 보내주신 링크가 있어서, 이 링크를 읽어보고 내가 하지 않은 부분을 찾아보면 되겠다.
참고한 문서에서는 로드밸런서의 헬스 체크 기준 체크, 로드 밸런서의 연결 해제(connection draining) 작업 관련 설정, ECR에서 도커 이미지를 업로드하는데 걸리는 시간 등을 고려하라고 말해주었다. 헬스 체크 기준은 위에 언급한 것처럼 각 요청 간의 시도 간격을 10초로 바꿔주어서 괜찮을 것 같았다. 도커 이미지의 경우는 크기도 크지 않을뿐더러 대부분의 github workflow의 시간은 ECS에서 배포하는 데 걸렸지 ECR에 도커 이미지를 업로드하는데 쓰고 있지 않았어서 이것도 원인으로 보지는 않았다. 몰랐던 부분은 '로드 밸런서의 연결 해제 과정'이었다.
서버에서 캡처해온 사진입니다
덕분에 ECS 서비스를 설정할 때 로드밸런서를 지정하는 것이 무슨 의미인지 조금이나마 더 알 수 있었다. ECS 서비스가 disable 되는 과정은 다음과 같았다.
ECS 서비스에서 로드밸런서에게 현재 로드밸런서에 연결 중인 클라이언트에 대해 연결을 끊으라고 요청한다. 그리고 로드밸런서가 클라이언트에 대해 커넥션을 끊었는지를 모니터링 한다. 이 요청을 받았을 때 로드밸런서는 바로 연결을 끊지 않고, 클라이언트(서버에 접속해 있는 브라우저나 앱 등의 클라이언트를 의미한다)가 keep-alive 커넥션을 끊었는지를 확인한다. 만약 끊지 않았다면 로드밸런서는 기본 설정된 값 동안 클라이언트가 keep-alive 커넥션을 끊기를 기다린다. 문서에서는 이 기본값(deregistration delay)이 300초로 설정되어 있다고 했다. 그렇다면 5분 뒤에 새로운 시도가 이어지는 것이 설명된다.
이 기본 시간이 지나면 로드밸런서는 자신과 연결된 클라이언트의 연결을 강제로 종료시킨다. 그러면 ECS 서비스에서 이것을 알 것이고, 그러면 해당 컨테이너의 프로세스를 종료시키는 SIGTERM 시그널을 보낸다. 그런데 그림처럼 컨테이너에 직접 시그널을 보내는 것은 또 아닌 것 같고, 컨테이너와 같은 namespace? network? 어쨌든 같은 도메인이나 무언가에 속해 있는 Agent에게 해당 요청을 보내면 해당 agent가 컨테이너에게 SIGTERM 시그널(혹은 요청)을 보내는 방식으로 이해했다.
서버에서 캡처해 온 사진입니다
이제 이 기본값이 300초로 설정된 deregistration delay 값을 바꿔주면 되겠다. 문서에서는 5초로 바꾸라고 해서 그렇게 해 보면 되겠다.
GPT는 바로 구체적인 방법을 잘 제시해 주었다. EC2>대상 그룹>설정에서 '등록 취소 지연(드레이닝 간격)'의 값을 확인해 보니 300초로 되어 있었다! 이걸 바로 5초로 바꿔주었다.
이제 임의의 변경사항을 develop 브랜치에 만들어서, github workflow의 실행 시간이 단축되는지를 확인해 보자.
단축은 되었다! 더 단축될 수 있는지는 모르겠지만 확실히 시간은 줄었다. 여전히 개발 서버에 내용이 반영은 되지 않는다... 직접 도커 이미지를 pull 받아서 확인해 보고 싶었지만, 예전에 unauthorized 에러가 났었다. 이쯤 되면 ECR에 최신 이미지가 안 올라오는 것이 아닌가? 하는 추측도 든다. 이 부분에 대해서는 내일 확인해 보면 될 것 같다.
✅ 궁금한 것
1. AWS 내부에서 사용하는 시그널 같은 것이 있나보다. (SIGTERM 시그널을 보낸다는 점에서 그런 추측을 했다) 어떤 시그널이 있고, 어떻게 시그널을 보내도록 되어 있는 것인지도 궁금하다.
1. github workflow는 오류 없이 실행되는데 정작 dev 서버와 develop 브랜치의 내용이 다르다. 어디에서 문제가 생긴 것일까? (개인적으로는 ECR의 도커 이미지가 최신이 아니거나 반영이 안 된 것일수도 있다고 생각한다)
오늘 아침에 갖게 된 의문점이자 새로 해결할 점들이다. 특히 1번의 경우는 현재 develop 브랜치에 머지 완료된 AI 투두 추천 API가 개발서버에 올라가있지 않기 때문에 서버에서 반영할 수 없다는 단점이 있었다.
GPT에게 물어보니 여러 가능성을 제시해주었다. 예를 들면 yml 파일에서 정의한 태스크 정의가 반영되지 않았을 수도 있고, 도커 이미지를 빌드할 때 캐시를 사용해서 이전에 사용하고 있던 도커 이미지를 사용하고 있을 수 있다는 가능성이 있었다. 여러 가지 가능성을 고려해야 했다.
우선은 도커 이미지를 빌드할 때 캐시를 사용하지 말고 가장 최근에 올린 브랜치의 내용을 반영시키기 위해서, 도커 빌드 커맨드에 --no-cache 옵션을 붙였다.
그리고 ECS 클러스터>서비스>태스크에 들어가서 현재 태스크가 사용하고 있는 태스크 정의가 가장 최신 버전인지도 확인했다. 현재까지 태스크 정의는 총 7개의 버전이 있는데, 다행히 가장 최근(7)버전을 사용하고 있었다.
알고보니 yaml 파일에서 사용하는 태스크의 정의의 버전이 latest가 아닌 2로 고정되어 있는 것 같았다. 그래서 바꿔줬다. (yaml 안에 태스크 정의와 관련된 json 파일을 지금은 raw string으로 넣고 있는데, 프론트 배포가 완료되면 조만간 고쳐보려고 한다.)
그런데 여전히 개발 서버와 develop 브랜치가 달랐다. 멘토님께도 여쭤보니 ECR에 도커 이미지를 올릴 때 latest 태그를 달면 인식을 못 하고, 커밋별로 고유하게 나오는 sha 값을 태그로 달아줘야 개별 도커 이미지를 인식할 수 있다고 한다.
기존에 :latest로 도커 이미지를 ECR에 push하거나 ECS에서 가져오는 태그들을 모두 latest 대신 고유한 커밋 스트링(표현이 맞는지 모르겠다)을 태그값으로 달도록 해 주었다. 이제 관련된 값을 다 바꿔주고, github workflow는 아마 큰 이상없이 올라갈 것이니 자고 나서 아니면 조금 있다가 이번에는 개발서버와 develop 브랜치의 내용이 같은지 확인해 보면 되겠다.
✅ 궁금한 점
1. 빌드가 너무 오래 걸리는 것 같은데(길면 20분이 걸린다) 어떻게 시간을 줄일 수 있을지 궁금하다.