
✅ 오늘 배운 것
그저께의 이슈가 오늘까지 이어지고 있다! 하지만 이 글을 쓰기 시작한 시점에 멘토님의 피드백과 설명을 듣고 문제가 무엇이었는지를 조금이나마 이해한 상황이라서, 오늘이면 이 이슈를 마무리할 수 있지 않을까 기대해본다.
일단 야심차게 시작하긴 했는데... 결론을 스포하자면 또 Invalid hook call 에러가 났다. 그래도 나름 삽질해서 애정이 있는 코드니... 일단 올려보자.
// Api.js
const handleRequest = async (request, headerFunction) => {
try {
const response = await request(headerFunction());
return response.data;
} catch (err) {
Sentry.captureException(err);
console.log('err', err);
if (
(err.response.status === 401 &&
err.response.data.detail === TOKEN_INVALID_OR_EXPIRED_MESSAGE) ||
err.response.data.detail === TOKEN_INVALID_TYPE_MESSAGE
) {
try {
const accessToken = await AsyncStorage.getItem('accessToken');
const refreshToken = await AsyncStorage.getItem('refreshToken');
const responseData = await axios.post(API_PATH.renew, {
refresh: refreshToken,
access: accessToken,
});
await AsyncStorage.setItem('accessToken', responseData.data.access);
const secondRequest = await request(headerFunction());
return secondRequest.data;
} catch (refreshError) {
if (refreshError.response.status === 401) {
router.replace('index');
} else {
throw refreshError;
}
}
} else {
throw err;
}
}
};
const fetchTodos = (userId, headerFunction) => {
return handleRequest(
header => axios.get(`${API_PATH.todos}?user_id=${userId}`, { header }),
headerFunction,
);
};
현재 문제가 발생한 코드는 이렇게 Api.js 파일에 정의된 함수들을 컴포넌트에서 가져와서 사용하는 방식으로 되어 있었다.
위의 프론트 이슈는 멘토님이 멘토링 시간 때 잠시 봐주시기로 했다. 이미 해당 이슈에 2시간을 넘게 쓴 상황이라, 더 이상의 시간을 쏟는 것보다 다른 이슈를 처리하는 것이 좋다고 판단했다. 그래서 백엔드로 Context Switching을 해 보기로 했다.
어제 작업하던 Locust로 API 부하 테스트하는 작업을 이어서 해 보려고 한다. 어제는 서버가 다운될까봐 쫄린 탓에 user를 1명으로 설정했지만, 이번에는 최대 유저 수를 100명으로 설정해 보았다. 그랬더니 다음과 같은 값을 얻었다.

초당 약 30-40개의 request를 처리할 수 있다면 어느 정도일까? 보통의 갓 런칭된 서비스라면 어느 정도의 RPS를 목표로 잡아야 할지, 그리고 RPS를 핵심으로 이 표를 보는 것이 맞을지도 헷갈린다.
그리고 지금은 단순 조회 API 하나만 테스트하고 있다. 그러나 실제 유저의 패턴은 훨씬 다양하고 분명 DB 조회뿐만 아니라 write를 하는 API도 불러올 것이기에, 이 API를 테스트 해봐야 겠다. 그러려면 테스트 환경에서 사용하는 DB는 테스트 DB로 별도 세팅이 필요하겠다.

GPT는 별도로 환경변수를 test DB를 가리키도록 설정해서 locust 스크립트를 돌리라고 말해주었다. 그런데 나는 그런 것보다 settings.py 환경파일에 test DB를 설정해놓으면 locust에서 해당 설정을 자동으로 참조하도록 해서 더 편하게 테스트를 하고 싶었다. 어떤 글에서도 나와 비슷한 사람을 발견했다.
일단은 별도의 테스트 환경에서 사용하기 위해서 RDS를 하나 더 만들어주자. 해당 값들을 AWS Secrets Manager에도 저장한 다음, settings 파일에도 테스트 DB와 관련된 설정을 하나 더 추가해줬다.
DATABASES = {
"default": {
"ENGINE": "django.db.backends.mysql",
"NAME": SECRETS.get("DB_NAME"),
"USER": SECRETS.get("DB_USER"),
"PASSWORD": SECRETS.get("DB_PASSWORD"),
"HOST": SECRETS.get("DB_HOST"),
"PORT": SECRETS.get("DB_PORT"),
},
"test": {
"ENGINE": "django.db.backends.mysql",
"NAME": SECRETS.get("TEST_DB_NAME"),
"USER": SECRETS.get("TEST_DB_USER"),
"PASSWORD": SECRETS.get("TEST_DB_PASSWORD"),
"HOST": SECRETS.get("TEST_DB_HOST"),
"PORT": SECRETS.get("TEST_DB_PORT"),
}
}
이제 이 테스트 DB 설정값을 어디서 불러와야 할까? 공식문서와 소스코드를 찾아보니 모든 태스크(부하 테스트)를 실행하기 전에 on_start 메소드를 호출하는 것 같았다.


기존에 사용하던 locust test 클래스에 on_start 메소드를 오버라이딩 해 주었다.
from locust import HttpUser, task
from django.conf import settings
class TestTodos(HttpUser):
def on_start(self) -> None:
test_db_info = settings.DATABASES.get("test")
self.db_host = test_db_info.get("HOST")
self.db_name = test_db_info.get("NAME")
self.db_user = test_db_info.get("USER")
self.db_password = test_db_info.get("PASSWORD")
이렇게 설정을 작성하고 'locust' 명령어를 입력하니 다음과 같은 에러가 났다.
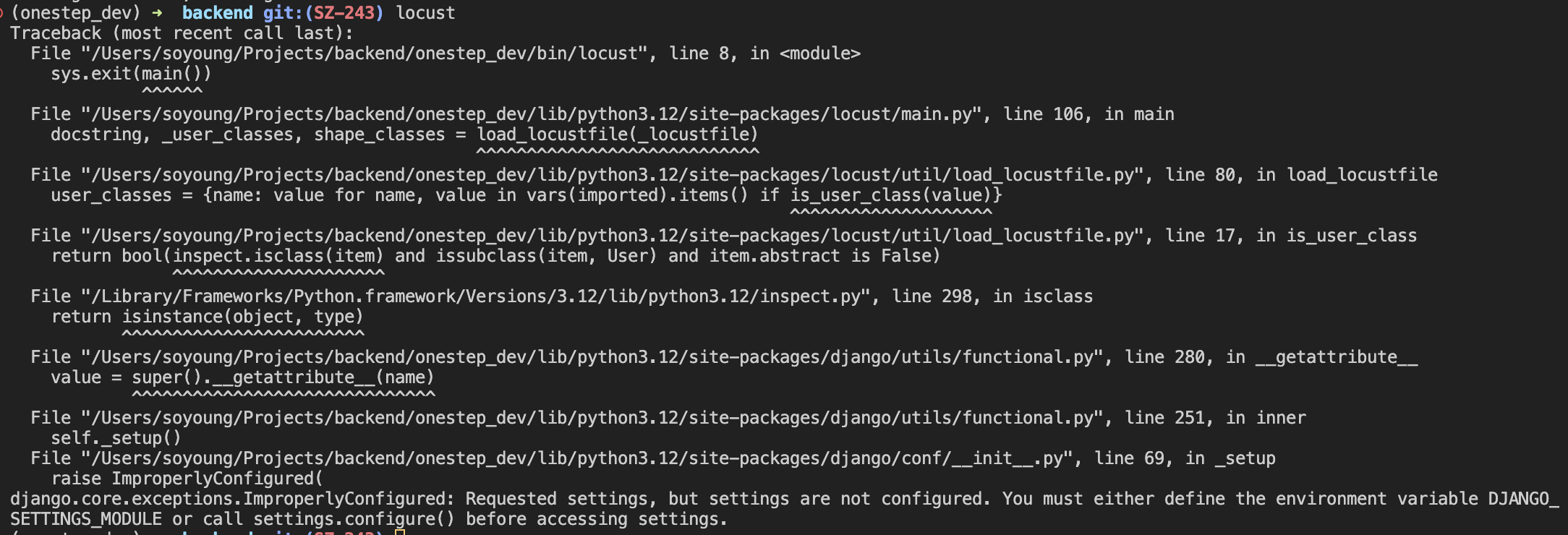
알고보니 django에서 settings 정보를 가져오려면, 다음과 같은 코드를 먼저 선언해 주어야 했다.
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "onestep_be.settings")
이유를 물어보았더니, 장고의 설정은 위에서 가져온 것처럼 django.conf.settings 모듈에서 관리된다. 그런데 이 모듈을 사용해서 설정 정보를 불러오기 전에 설정이 로드되지 않으면 ImproperlyConfigured 예외가 발생한다고 한다. 그렇기 때문에 django.conf.settings에서 불러올 환경이 어떤 기본값을 사용할지를 os.environ.setdefault() 함수를 통해 설정해 주어야 예외가 발생하지 않는다.

해당 에러를 해결하고 Locust의 로컬 서버를 띄웠다. 그랬더니 API에서 정상 반응을 리턴하지 않고 401, 500 에러가 떴다. 테스트 서버라서 유저 객체가 없었기 때문에 500 에러가 났고, 해당 API는 액세스토큰이 있는 유저에게만 401 응답을 리턴했기 때문이다.

이럴 경우엔 여러 가지 방법을 사용할 수 있어 보인다. GPT가 제시한 방법들 중 '사전에 발급된 액세스토큰 사용'이나 '프론트 URL을 통한 인증 절차 거치기'는 번거롭기도 하고 프론트가 웹이 아니라 앱이기 때문에 사용하기 어려웠다. 그래서 테스트 환경으로 실행할 시 인증을 건너뛰도록 설정해 봐야겠다. 테스트 환경에서는 모든 API에 대해서 인증을 잠시 우회할 것이므로, 특정 뷰에서만 동작하는 dispatch 메소드를 사용하는 대신 미들웨어를 사용하는 것이 더 간단하다고 판단했다.
우선 test.py라는 파일을 settings에 만들어 주고, 인증을 건너뛸지에 대한 여부를 저장하는 SKIP_AUTHENTICATION 변수를 settings.py에 정의했다. 기본값은 False였다. test.py 파일에서만 이 변수를 True로 세팅해 주었다. 이제 테스트 환경에서는 이 test.py에 설정된 환경을 가져오면 되겠다.
그리고 테스트 환경에서 서버가 실행될 경우 추가로 동작할 미들웨어 클래스도 정의해주었다.
from django.conf import settings
class SkipAuthMiddleware:
def __init__(self, get_response):
self.get_response = get_response
def __call__(self, request):
if settings.SKIP_AUTHENTICATION:
request.user = None
response = self.get_response(request)
return response
다만 해당 미들웨어 클래스는 테스트 환경에서만 동작해야 하므로, 테스트 환경 설정 파일에서만 아래와 같은 로직을 추가해서 MIDDLEWARE 변수의 맨 앞에 해당 미들웨어를 추가해 주었다. 미들웨어는 chain 구조로, 순서대로 사용자의 요청을 받고 그 반대 순서로 응답을 리턴하게 되어 있다. 따라서 맨 처음 요청을 받아 이를 승인해 주려면 MIDDLEWARE 변수 중 맨 앞에 해당 미들웨어를 넣어 주어야 하겠다.
# test.py
from onestep_be.settings import *
SKIP_AUTHENTICATION = True
if SKIP_AUTHENTICATION:
MIDDLEWARE.insert(0, "accounts.middleware.SkipAuthMiddleware")
그런데 고민이 생겼다. 지금 서버는 개발 서버와 프로덕션 서버 2개로 되어있다. 그래서 테스트 환경을 실행할 별도의 서버가 없다. 처음에는 기존 API URL에 '/test'만 붙인 테스트 전용 API를 만들어야 하나 고민도 되었다. 하지만 팀원과도 얘기해본 결과 그냥 별도의 테스트 환경이 하나 더 있으면 좋겠다는 결론이 나왔다.
그래서 develop 브랜치와 똑같은 코드를 배포하는 테스트 서버를 만들어야 하겠다. 즉 하나의 브랜치를 사용해서, 두 개의 서버를 다른 환경으로 띄워야 하는 상황이다.

처음에는 워크플로우 하나에 여러 개의 Job을 만들어서 해당 작업을 해야 하나, 아니면 별도의 워크플로우를 만들어서 작업해야 하나 고민했었다. 그러나 현재 ECR에서 도커 이미지에 태그로 달고 있는 값이 github.sha 값인데 이 값은 워크플로우가 가지는 고유한 값이므로, 두 개의 서버(개발 서버와 테스트 서버)가 모두 같은 도커 이미지를 참조해야 한다고 생각했다. 왜냐하면 어차피 두 서버는 모두 같은 브랜치의 내용을 반영할 건데 굳이 같은 하나의 이미지를 참조하면 될 일을 두 개의 다른 이미지를 각자 참조하게 만들 필요가 없기 때문이다.
...라고 생각했는데, 생각해보니 도커 이미지는 도커파일을 통해 만들어지는데, 두 환경에서 사용하는 도커파일이 달랐다. 그러므로 두 서버에서 사용하는 이미지들은 별개의 워크플로우를 사용해서 별도의 도커 이미지들로 만들어주는 것이 맞겠다. 그러므로 해당 작업은 별도로 하나의 워크플로우를 더 파서 진행하자.
그런데 또 고민이 생겼다.
그러면 하나의 서버가 더 필요한 것은 알겠다. 그런데 이를 별도의 클러스터를 하나 더 만들어서 진행할지, 아니면 같은 클러스터 안에서 서비스를 더 만들어서 진행할지, 그것도 아니면 같은 서비스 내에서 태스크를 하나 더 만들어서 진행할지를 모르겠다는 것이다. 멘토님은 정확히 잘 모르면 일단 해 보고 나중에 고치라는 방향으로 피드백을 주셨어서, 일단은 별도의 클러스터를 하나 만들어서 진행해 보려고 한다. 그러니까 현재 ECS에는 개발, 프로덕션, 테스트 이렇게 총 세 개의 클러스터가 있게 되겠다.
다시 멘토링 시간에는 프론트엔드로 Context Switching을 해 보았다. 애를 먹던 커스텀 훅 사용 문제가 있었는데, 멘토님의 피드백으로 도달한 결론은 커스텀 훅을 사용하는 대신 AsyncStorage로 토큰의 값을 저장소에서 가져오고, 토큰 값이 바뀔 때만 해당 값을 업데이트 해 주는 방법이었다. 이 방법도 크게 두 가지로 구현할 수 있었다.
첫 번째는 javascript class를 사용해서 Api 클래스를 구현하고, 그 안에 필드(멤버 변수)로 액세스 토큰값을 갖고 있는 방법이었다. 두 번째는 액세스 토큰값을 담은 전역변수를 사용해서 맨 처음엔 AsyncStorage에서 초기 액세스 토큰값을 가져온 뒤, 만약 값이 업데이트되면 해당 변수의 값을 바꿔주는 방법이었다. 두 방법 모두 동작했다.
그러나 첫 번째 방법이 좀 더 '객체지향적'이고 코드를 한 눈에 이해하기가 편하다고 판단했기에, 로직이 조금 더 복잡해져도 클래스를 통해 로직을 구현해보려고 한다.
그런데 이슈를 작업하고 블로그도 쓰다 보니 벌써 10시라서... 오늘은 여기까지만 하고 내일 위에서 언급한 부분들을 마저 마무리하자.
+ 이력서와 중간발표 대본 초안도!
✅ 궁금한 점 / 논의점 / 보완점
1. 테스트 DB로 사용하려는 RDS는 어떻게 관리해야 할까? 예를 들면 해당 RDS는 테스트 때만 요청을 처리하고 나머지는 IDLE한 상태로 있는데, 이럴 때는 그대로 두는 게 맞을지 아니면 테스트 때만 활성화하는 것이 맞을지 모르겠다.
2. LazyObject는 무엇일까? Lazy Loading이라는 말은 들어보았는데 추측해보면 이와 비슷한 맥락 같다.
3. (사실상 1번과 같은 고민) 테스트 서버를 하나 더 띄워두면 서버 유지 측면에서 뭔가 비용 등이 들 것 같아서, 이를 테스트 할 때만 켜 둬야 할지 고민이다. 그렇다고 매번 테스트를 할 때마다 테스트용 서버를 띄웠다 내렸다 하는 것도 번거로워 보이는데... 보통 기업이나 서비스에서는 어떻게 하는지도 궁금하다.
4. 테스트 서버를 어디다 띄워야 할지 고민이다. 별도의 클러스터? 개발 서버와 같은 클러스터에 있는 별도의 서비스? 아니면 개발 서버와 같은 서비스에 있는 별도의 태스크? 어떻게 하면 좋을지 고민이다. 아무래도 내가 ECS의 '클러스터', '서비스', '태스크'의 개념이 각각 정확히 무엇을 의미하는지를 잘 몰라서 이런 고민을 하는 것 같으니, 이 부분에 대한 정의도 찾아보자!
'개발 일기장 > SWM Onestep' 카테고리의 다른 글
| 20240816 TIL: uvicorn+gunicorn으로 서버 성능 향상시키기 & 액세스토큰 갱신시키는 Api 클래스 싱글톤 패턴으로 만들기 [진행중] (0) | 2024.08.16 |
|---|---|
| 20240815 TIL: uvicorn+gunicorn으로 서버 성능 향상시키기 [진행중] (0) | 2024.08.15 |
| 20240813 TIL: 리액트의 커스텀 훅을 사용해서 요청에 최신값 헤더 넣어주기 & API 서버 부하 테스트 해보기 (0) | 2024.08.13 |
| 20240812 TIL: 개발 환경 분리 & react custom hook 만들기 (0) | 2024.08.12 |
| 20240811 TIL: github workflow에서 최신 브랜치의 내용이 반영되지 않는 문제 수정 & 개발 환경 분리 (0) | 2024.08.11 |