이번에는 아까와 비슷하지만, url 주소 뒤의 쿼리(query) 형식으로 받은 변수를 json 형식으로 출력하는 코드이다.
DemoApplication.java, Greeting.java, GreetingController.java 3개의 클래스를 사용한다.
Greeting.java는 모델로 사용될 객체이다. json 형식으로 출력할 때, 어떤 필드들을 출력할지를 이 클래스에 정의해 놓는다.
Greeting.java
(참고한 포스트에 있는 코드 원본을 그대로 가져왔다.)
package com.example.restservice;
public class Greeting {
private final long id;
private final String content;
public Greeting(long id, String content) {
this.id = id;
this.content = content;
}
public long getId() {return id;}
public String getContent() {return content;}
}
id와 content 필드는 모두 private, final 이므로 한 번 생성하면 변경할 수 없고, 외부에서 값을 바꾸려고 시도할 수 없다.
GreetingController.java
(참고한 포스트에 있는 코드 원본을 그대로 가져왔다.)
package com.example.restservice;
import java.util.concurrent.atomic.AtomicLong;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class GreetingController {
private static final String template = "Hello, %s!";
private final AtomicLong counter = new AtomicLong();
@GetMapping("/greeting")
public Greeting greeting(@RequestParam(value = "name", defaultValue = "World") String name) {
return new Greeting(counter.incrementAndGet(), String.format(template, name));
}
}
Greeting.java 에서는 id 필드가 long 타입이었는데, GreetingController에서는 굳이 AtomicLong 타입의 래퍼 클래스(Wrapper Class)를 사용했다. long 타입을 객체로 할 이유는 없지만 아마도 AtomicLong 클래스의 incrementAndGet 메소드를 사용하려는 의도인 것 같다.
#3
서버 포트 변경
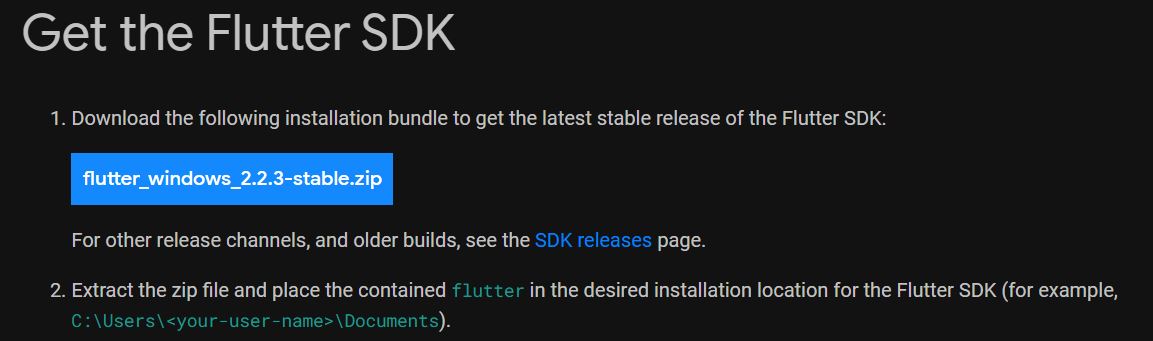
나는 이전에 사용하던 django 프로젝트에서 8080번 기본 포트를 미리 사용하고 있었기 때문에, spring을 실행해도 웹 페이지가 나오지 않았다.
이런 경우에는 본인의 프로젝트 이름을 P라고 하면, 'P>src>main>resources>application.properties' 파일에 서버 포트를 따로 변경해주면 된다.
+application.properties 파일은 서버 포트를 바꾸거나, 기본 DB 대신 다른 DB를 사용하는 등 기본으로 설정된 사항을 바꿀 때 추가적인 옵션을 입력하는 파일이다.
server.port = 1000
이렇게 한 줄만 입력하면, 다음부터 실행할 때 1000번 포트로 연결된다.
+ spring 공식 홈페이지의 accessing data with mysql 포스트를 보면서 정리한 ORM 개념
hibernate는 무엇인가 싶어 검색해보니, 'Java 환경에서 제공하는 ORM 솔루션'이라고 한다.
그럼 ORM은 뭘까?
ORM: Object Relational Mapping
ORM이 왜 필요한가?
보통 프로그램을 작성하면서 여러 객체(object)를 만든다. 그러나 DB를 사용하는 경우 이 객체와 DB 안의 테이블을 연결해야 한다. SQL을 사용하여 직접 코드를 작성할 수도 있지만, SQL 코드를 사용할 필요 없이 프로그램에서 작성한 코드가 자동으로 DB에 해당 객체와 연결될 수 있는 테이블을 만들도록 할 수 있다. ORM 개념으로 이게 가능하다. (다만 모든 DB에 해당하는 얘기는 아니고, '테이블'이라는 개념이 있는 관계형 데이터베이스(Relational Database)에 해당한다고 한다.)
영상을 다 보지 않아서 모르지만, ORM이란 아마도 객체(object)와 데이터베이스를 서로 연결지어 맵핑(relational mapping) 하는 원리 또는 개념인 것 같다. Spring, Java에서도 당연히 이 ORM 개념이 있으며, 영상에서는 hibernation 개념도 이와 관련이 있다고 한다.
: WAMP란, apache, mysql, php를 한 번에 다운로드할 수 있는 Bitnami 패키지이다.
장점 : 다운로드 과정이 간편함.
단점 : mysql 사용 시 mysql 서버를 키고 + cmd(command prompt 창)를 켜고 접속해야 함. 간단하지만 번거로울 수 있음.
=> 나는 (2)번 다운로드.
* 7.x 이후의 8.x 버전부터는 wamp로 설치해도 mysql 대신 mariadb라는 이름의 데이터베이스가 설치되는데, 알고보니 mysql을 만들었던 개발자가 후에 mariadb라는 이름으로 다시 만들었다는 얘기가 있다. (현재의 mysql은 oracle에 속해 있는데, 그 과정에서 지금의 mysql은 oracle에 속하게 되고 이 mysql과 기능은 똑같은 mariadb가 따로 생긴 것 같다.)
<mysql의 특징>
1. mysql은 데이터베이스이므로 보안이 중요하다.
b/c 권한이 없는 외부에서 멋대로 데이터를 변경하거나 빼 나가는 것을 막기 위함이다.
=> 그래서 해당 mysql 데이터베이스의 최고 권한을 가지는 root user, 최고 사용자를 설정하는 작업이 꼭 있다.
root 사용자의 이름을 따로 설정할 수도 있고(선택사항), 이에 따른 비밀번호는 반드시 설정해야 한다(강제, 필수).
2. root 사용자 계정으로 로그인하면, 다른 사용자에게, 어떤 범위의 권한을 부여할지까지도 설정할 수 있다.
ex) 사용자 A에게 데이터베이스 aa의 관리 권한을 부여하고, aa의 비밀번호를 a'로 설정할 수 있다.
이 경우, 로그인할 때 사용자 이름을 A로, 비밀번호를 a' 로 입력하면 사용자 A의 권한으로 데이터베이스를 사용할 수 있다.
* 다만 사용자 A는 모든 데이터베이스의 관리 권한을 가진 것이 아니므로, aa가 아닌 다른 데이터베이스를 관리할 수는 없다.
또한 root 사용자가 바로 delete문을 사용해서 사용자 A의 권한을 제거할 수도 있다.
=> 그러므로, 생활코딩 강의에서는 계정의 중요한 설정을 하는 것이 아니면 다른 사용자 계정을 만들어서, 그 계정에서 데이터베이스를 관리할 것을 권했다.
(mysql 문법을 배우고 설치 및 구축을 하는 데 생활코딩 강의의 도움을 많이 받았다.)
2) mysql과 java 프로그램을 연결한다. (연결하는 driver/connector를 설치, 지정한다)
-> 또 다른 방법도 있겠지만, 여기서는 mysql Connector를 설치해서 사용한다.
(지금은 spring 프레임워크 등에서 다양한 방법이 많다고 하더라)
(1) mysql 홈페이지에서 connector를 다운로드 받는다.
(2) eclipse의 경우,
: 해당 프로젝트 우클릭 -> properties -> 왼쪽의 여러 옵션 중 Java Build Path -> ClassPath => Add Jars -> connector jar의 경로 지정.
2. mysql 코드를 입력한다.
: 데이터베이스를 만들고, 테이블을 만든 뒤 데이터를 넣어 보는 것까지!
* 코드 치기 전 주의 *
: 운영체제에 따라 대/소문자 구분 여부가 다르다!
Window는 대소문자 구분을 하지 않아서, 아래의 코드를 소문자로 입력해도 상관이 없다.
<-> 그러나 다른 Mac OS, Linux 등의 경우 대소문자를 구분하므로, 아래의 검정 글자는 반드시 대문자로 입력해야 한다.
(1) 데이터베이스 만들기
: 처음 시작할 때는 테이블도 없고, 테이블들을 모아 둘 데이터베이스도 없다. 그러므로 우선 데이터베이스를 먼저 만들고, 그 안에 테이블을 만드는 방식으로 접근해야 한다.
: CREATE DATABASE 데이터베이스 이름;
CREATE DATABASE BBS;
(2) 데이터베이스 안의 테이블 만들기
: 여기서의 데이터베이스는 mysql 데이터베이스 전체를 의미하는 게 아니다.
테이블이 하나의 파일이라고 하면, 여기서의 데이터베이스는 관련 파일들을 하나로 묶어 주는 폴더이다. 의미가 헷갈릴 경우 스키마(schema)라고도 하지만, 데이터베이스라는 용어가 더 일반적이다.
[1] 테이블을 만들기 전에, 어떤 데이터베이스를 사용할지를 먼저 지정해 줘야 한다.
데이터베이스가 하나일 때도 마찬가지다. 혼선을 방지하기 위해서 먼저 사용할 데이터베이스 이름을 지정한다.
: USE 데이터베이스 이름;
USE BBS;
[2] 데이터베이스 안에서 사용할 테이블을 만든다.
: CREATE TABLE 테이블 이름(테이블에 쓰일 column 설정);
column의 경우, 보통은 이런 특징을 가진다:
: ( column 이름column의 자료형(글자 수)null 여부기타사항 );
여러 column을 나열한 후, 마지막에는 반드시 primary key를 지정해 줘야 한다.
* primary key : 데이터베이스의 각 행(record)을 구분하는 기준이 되는 column으로, primary key로 지정된 column에서는 값이 중복될 수 없다.
: PRIMARY KEY(column 이름));
마지막은 이렇게 마친다.
column의 자료형은 INT(보여줄 글자 수), VARCHAR(저장할 글자 수), TEXT, EMAIL, DATETIME 등 매우 다양하다.
(글자 수)를 입력해야 하는 자료형이 있고 아닌 자료형도 있다.
null 여부는 NULL(입력하지 않아도 됨) 또는 NON NULL(반드시 입력해야 함) 으로 입력하면 되는데, primary key인 경우는 null로 입력할 수 없으니 주의하자. (바로 아래처럼 추가적인 경우는 예외)
+ 많은 테이블에서 종종 ID column을 사용하고, ID column을 primary key로 사용한다. 그런데 보안의 의미가 아니라 일련번호의 의미로 쓰인다면, 일일이 값을 입력하기 귀찮다.
=> 데이터가 추가될 때마다 ID의 값이 자동으로 1씩 증가하도록 기타사항에 코드를 추가할 수 있다.
이렇게!
: AUTO_INCREMENT, ~ 다른 내용 이어짐
테이블 생성 예시:
CREATE TABLE USER(
userID INT(11) NON NULL AUTO_INCREMENT,
userPassword VARCHAR(20) NON NULL,
userName VARCHAR(20) NON NULL,
userGender VARCHAR(10) NULL,
userEmail VARCHAR(30) NULL,
PRIMARY KEY(userID)
);
(3) 데이터베이스 안에 데이터 입력하기(INSERT)
INSERT SQL 문을 사용해서 각 column에 데이터를 입력해 준다.
* 이때 NON NULL인 column의 값을 입력하지 않으면 오류가 발생한다.
: INSERT INTO 테이블 이름 (column 1, column 2, column 3, ... , column n ) VALUES (value 1, value 2, value 3, ... , value n);
이때, 모든 column의 값을 다 입력하는 경우 (column1, ... , column n) 부분은 생략이 가능하다.
또한 테이블 이름과 VALUES는 나열한 값의 순서대로 각각 매칭된다.
반드시 테이블 이름() 안의 column 개수와, VALUES() 안의 값의 개수가 같아야 오류 없이 매칭된다.
+ 데이터 값으로 SQL 함수를 사용할 수 있다.
Ex. DATETIME의 경우, 현재 시간을 데이터로 넣고 싶다면 NOW() 함수를 이용하기도 한다.
문자열을 VALUES() 안에 넣는 경우, ""이 아니라 '' 안에 넣어줘야 한다.
<-> 그러나 column 이름은 () 안에 넣어도 "" 이나 ''을 쓰지 않는다.
예시:
INSERT INTO USER(userID, userPassword, userName) VALUES(14, 'sicnek##321', 'sinnz');
get_prime 메소드는 매개변수도 없고 출력값(리턴하는 값)도 없는 메소드인데, prime이라는 배열은 어디서 가져왔나?
get_prime() 메소드 위에다가 먼저 prime이라는 정적 boolean 타입의 필드를 선언해 주었다. 이렇게!
public static boolean[] prime; // main 메소드 밖에서 선언
나는 정적 필드를 선언할 생각은 못 했는데, 생각해 보니 정적 필드를 선언하고 그 필드를 정적 메소드에 언급하면 굳이 로컬변수나 객체를 생성하지 않아도 되겠다.
이렇게 위에서 정적 필드를 선언하고, 나중에 main함수 안에서 prime 배열의 길이만 선언해 주면 된다.
N+1의 길이로 설정해서 0부터 N까지의 소수값 여부를 저장할 수 있는 배열을 만들어 준다.
(정적 필드 prime배열을 N+1의 길이로 설정한 것도, 그냥 0부터 N까지의 수들 중 소수를 다 구해버리고 나중에 M에서 N 사이에 있는 소수 값만 추출하기 위해서인 것 같다. prime배열을 M부터 N까지 선언한다면 기존 에라토스테네스의 체 알고리즘을 일부 변형해야 되서 번거로운 점도 있을 듯.)
prime = new boolean[(N+1)]; // main 메소드 안에서 설정
에라토스테네스의 체 알고리즘은 2개의 중첩 for문으로 구성된다.
1. 여기선 true이면 소수가 아니고 false면 소수라고 간주한다.
2. 이는 어떤 수의 배수는 모두 소수에서 제외한다는 원리를 이용한다.
첫 번째 for문에서의 i는 어떤 수의 역할을 한다.
두 번째 for문에서의 j는 어떤 수의 배수 역할을 한다.
좀 더 구체적으로 보면,
1. 0과 1은 소수가 아니고 2는 소수라서, i=2부터 시작한다.
2. j는 i*i이다. i*i는 i라는 약수를 갖기 때문에 소수에서 제외된다.
3. 이 j에다가 i씩 더한다. 즉 i*i, i*(i+1), i*(i+2), ... 이렇게 해서 i를 약수로 갖는 모든 값들을 제외시킨다.
4. 그 다음은 i=3, 위의 과정을 반복한다. 그런데 만약 i=4처럼 소수가 아닌 값이 i 자리에 와도 이미 i=2일 때 j의 값에 해당되어서 제외되었기 때문에 상관 없다.
5. 이렇게 N까지 반복하는 것이 아니라, N에 루트 씌운 값까지만 반복한다. 그 이후의 값은 검사할 필요가 없다.
+) 5번의 이유:
어떤 자연수 N은 1과 자신이 아닌 다른 두 수 A와 B의 곱으로 나타낼 수 있다고 해 보자. (즉 N은 소수가 아니다.)
A * B = N이다.
그런데 만약 A가 N의 제곱근보다 크다면, 나머지 B는 반드시 N의 제곱근보다 작아야 한다. 안 그러면 A*B는 N보다 큰 값을 갖게 되어서 식이 성립하지 않는다.
=> 즉 N이 소수가 아니라고 가정할 때, N의 제곱근까지만 검사하면 합성수 N을 이루는 두 수 A, B중 작은 수(여기서는 B)까지는 검사할 수 있고, 만약 여기까지 검사했을 때 N의 약수가 나오지 않는다면?
=> B가 없는 것이므로 A*B = N 이라는 가정이 깨지게 된다. 고로 이때 N은 소수가 아니라고 볼 수 있다.
=> N의 제곱근까지만 검사하면 N이 소수인지 아닌지를 알 수 있다!
아무튼 그래서 get_prime() 정적 메소드를 선언해서 N까지의 수 중에서 소수인 값만 찾아 준다.
그 다음에는 main함수에서 해결하면 되는데,
1. if문에서 최솟값인 M이 최댓값인 N보다 큰 예외 상황 및 M, N이 0과 10000 사이가 아닌 예외 경우를 따로 처리한다.
2. 초기 sum 값은 0, min값은 int 타입이 가질 수 있는 가장 큰 값으로 설정하고, 바꿔 나간다.
** 왜 min 값을 0이 아니라 최댓값으로 설정하는지는 잘 모르겠다...!
int sum = 0;
int min = Integer.MAX_VALUE;
// Integer 클래스 안에 MAX_VALUE라는 final static 필드가 선언되어 있어서 이렇게 불러올 수 있나보다.
그리고 정적 필드 prime의 각 원소를 for문을 사용해서 하나씩 해당 값이 false인지(=소수인지) 비교하는데, 만약 false라면 sum 값에다 더해 주고, min 값으로 할당해 준다.
for(int i=M; i<=N; i++) {
if(prime[i]==false) {
sum += i;
if(min==Integer.MAX_VALUE) {
min = i;
}
}
}
이때, prime의 해당 원소의 값이 false일 때 min의 값을 i로 할당해 줘야 한다.
이렇게 조건을 주면, min값이 초기에 설정한 Integer.MAX_VALUE일 때만 min 값을 i로 할당하는데,
그러면 min값은 한 번만 할당되고 여러 번 변경되지 않는다.
마지막으로, 만약 M부터 N까지의 범위에 소수가 없었을 때, 즉 sum == 0일 때의 조건만 지정해 준다.
1. 입력을 받아야 하므로 Scanner(BufferedReader를 쓰지 않아도 시간 초과가 안 되었다.)
2. N의 약수에 해당하는 수를 저장할 ArrayList. 소인수가 몇 개일지 몰라서 배열 말고 ArrayList를 사용했다.
2. 정적 필드
9-2를 풀면서 정적 필드, 메소드를 잘 활용하면 객체 생성이나 로컬변수 처리 문제를 안 겪어도 된다는 생각에 정적 필드와 메소드를 선언했다.
public static int N;
public static ArrayList<Integer> number = new ArrayList<Integer>();
public static int i = 2;
1. N : scanner로 입력받을 N을 다른 메소드에서 다시 정의하기 귀찮아서 정적 필드로 선언.
2. ArrayList도 위에서 import만 해 주면 static field로 선언할 수 있었다...!
3. i는 while문에서 하나씩 증가시키고 해당 조건에 맞으면 소인수로 ArrayList에 추가시킬 수인데, 로컬 변수로 선언했다가 괜히 처리하기 까다로워질 것 같아서 정적 필드로 선언했다.
3. 정적 메소드 선언
자연수 N이 주어지면 해당 자연수를 소인수분해하는 isDivisor() 메소드를 선언하였다.
public static void isDivisor(int N) {
if(N==1) { // 예외1 : N=1일 때
System.out.println("");
}else if(N<0 | N>10000000) { // 예외2 : N이 범위를 벗어날 때
System.out.println("Error");
}else {
while(true) {
if(N==i) { // case 1
number.add(i);
break;
}else if(N % i != 0) { // case 2
i++;
}else if(N % i == 0) { // case 3
N = N/i;
number.add(i);
}
}
for(int k=0; k<number.size(); k++) {
System.out.println(number.get(k));
}
}
}
case 1:
소인수분해가 다 완료되고 더 이상 인수(혹은 약수)가 없으면 나눠지고 남은 수인 N과 나눌 수인 i가 서로 같아진다. 이 경우에만 while문을 break하도록 했다.
case 2:
N이 i로 나눠지지 않을 때 = i가 N의 소인수가 아닐 때.
i+1을 해서 값만 변화시켰다.
case 3:
N이 i로 나눠질 때 = i가 N의 소인수일 때.
우선 N을 i로 나눠서 N 값을 변화시키고, 해당 i값을 ArrayList에 추가했다.
i값을 증가시키지 않았으므로, 만약 N이 i로 여러 번 나눠지는 수였다면 그만큼 i가 추가로 ArrayList에 추가되도록 했다.
그리고 이렇게 만들어진 number이라는 ArrayList를 0번부터 끝까지(ArrayList의 size -1까지) 출력시켰다.
4. main 메소드
앞에서 메소드와 필드로 모든 과정을 선언해서 main메소드는 짧게 작성할 수 있었다.
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
N = sc.nextInt();
isDivisor(N); // 3번에서 작성한 isDivisor 정적 메소드 사용
sc.close(); // scanner 꼭 닫아주기!
}
Step 9-4. 소수 구하기(1929번)
이 문제도 혼자 풀었다.
<접근>
Step 9-2의 에라토스테네스의 체의 원리를 그대로 활용했다.
다만 아까는 int타입의 sum 변수를 사용한 대신, 지금은 에라토스테네스의 체로 0부터 N까지의 소수를 구한 뒤, M부터 N까지의 소수만 출력하는 방식을 사용하였다.
import java.util.Scanner;
public class Main {
// 정적 필드 선언
public static int M;
public static int N;
public static boolean[] prime;
public static void main(String[] args) {
// 정적 메소드에 사용할 값 할당하기
Scanner sc = new Scanner(System.in);
M = sc.nextInt();
N = sc.nextInt();
prime = new boolean[(N+1)];
if(M>=1 && N>=M && N<=1000000) {
get_prime(); // 정적 메소드 사용
// 정적 메소드에서는 1~N의 소수를 구했으나, M~N의 소수만 출력
for(int i=M; i<prime.length; i++) {
if(prime[i]==false) {
System.out.println(i);
}
}
}else { // 예외처리 : M과 N의 범위가 잘못되었을 때
System.out.println("ERROR");
}
sc.close();
}
// 정적 메소드 선언
public static void get_prime() {
prime[0] = true;
prime[1] = true;
for(int i=2 ; i<=Math.sqrt(N) ; i++) {
for(int j=(i*i); j<prime.length; j += i) {
prime[j] = true;
}
}
}
}
Step 9-5(4948번)
이것도 혼자 풀었다! 사실 에라토스테네스의 체 원리만 알면 쉽게 풀 수 있는 문제인 것 같다.
<원리>
9-2, 9-4와 마찬가지로 에라토스테네스의 체 알고리즘은 정적 메소드로 선언해 놓은 상태에서 시작하면 편하다.
다만 여기는 여러 개의 test case가 주어지고, 각각 한 줄씩 주어지며, 몇 개가 주어질지 모른다는 점에서 주의해야 한다.
1. N의 입력 여러 개 받기
이때 N은 몇 개가 나올지 모르고 한 줄씩 나오므로, StringTokenizer 등을 사용하지 않아도 분리가 되었다. 나는 원래 분리된 걸 분리하려고 하느라 애를 먹었는데, 원래 스캐너는 입력을 하면 한 줄 단위로 처리하는 거였다.
다만 여러 줄을 입력하고 언제 끝날지 모른다는 점에서 for문보다는 while문이 사용하기 적합했다.
-> 그래서 main메소드 영역을 이렇게 작성했다.
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
while(true) {
N = Integer.parseInt(sc.nextLine().trim());
if(N==0) {
break;
}
if(N<1 | N>123456) {
System.out.println("ERROR");
break;
}else {
prime = new boolean[((2*N)+1)];
get_prime();
}
}
sc.close();
}
입력의 마지막에 0이 주어진다는 말은, 0이 입력으로 주어지면 프로그램을 종료시키라는 말과 같다.
그래서 while문을 두고 break하는 조건을 N==0일 때로 지정했다.
+ 또한 N은 sc.nextLine()으로 입력을 한 줄씩 받아서 처리하도록 했다.
+ N 뒤에는 trim() 메소드를 써서, 혹시나 공백과 섞인 문자열이 들어갔을 때 숫자만 추출할 수 있도록 했다.
2. 에라토스테네스의 체 원리를 이용 + 문제에 맞게 get_prime 정적메소드 다시 정의
우선 정적 메소드에서 사용할 정적 필드를 먼저 정의했다.
public static int N; // main 메소드에서 입력 받을 때 사용
public static boolean[] prime; // 많은 숫자들 각각이 소수인지 아닌지를 저장하기 위한 배열
public static int count = 0; // 특정 범위에서 소수의 숫자를 세기 위한 int 타입 필드
public static void get_prime() {
count = 0; // N이 새로 바뀌어서 메소드가 새로 호출될 때마다 count를 0으로 초기화한다.
prime[0] = true;
prime[1] = true;
if(N==1) { // N=1이면 i=2로 시작해서 소수를 셀 수 없으므로 예외로 처리했다.
System.out.println(1);
}else if(N==0) {
System.out.println("");
}else { // 에라토스테네스의 체 알고리즘 그대로 사용
for(int i=2 ; i<=Math.sqrt((2*N)) ; i++) {
for(int j=(i*i); j<prime.length; j += i) {
prime[j] = true;
}
}
//N보다 크고 2N보다 작은 소수들만 출력
for(int i=(N+1) ; i<=(2*N) ; i++) {
if(prime[i]==false) {
count ++; // 소수 하나 나올 때마다 count + 1
}
}
System.out.println(count);
}
}
최종 코드는 이렇다.
package ml.app2;
import java.util.Scanner;
public class Main {
public static int N;
public static boolean[] prime;
public static int count = 0;
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
while(true) {
N = Integer.parseInt(sc.nextLine().trim());
if(N==0) {
break;
}
if(N<1 | N>123456) {
System.out.println("ERROR");
break;
}else {
prime = new boolean[((2*N)+1)];
get_prime();
}
}
sc.close();
}
public static void get_prime() {
count = 0;
prime[0] = true;
prime[1] = true;
if(N==1) {
System.out.println(1);
}else if(N==0) {
System.out.println("");
}else {
for(int i=2 ; i<=Math.sqrt((2*N)) ; i++) {
for(int j=(i*i); j<prime.length; j += i) {
prime[j] = true;
}
}
for(int i=(N+1) ; i<=(2*N) ; i++) {
if(prime[i]==false) {
count ++;
}
}
System.out.println(count);
}
}
}
에라토스테네스의 체 알고리즘을 알고 있었으나, 여기서는 주어진 짝수를 소수의 합으로 나타내되, '두 소수의 차가 가장 적은 쌍으로 나타내라'는 조건이 추가적으로 붙어서 그 점이 어려웠던 것 같다. 그래도 내가 생각한 범위에서의 예제 데이터는 처리할 수 있었는데, 왜 오류가 난 것인지는 잘 모르겠다ㅠㅠ
* IndexOutOfBoundsException 예외가 특히 많이 나왔는데, 어디서 나왔는지를 모르겠다...!
일단 풀이 시작>>
<보완할 점>
블로그 글을 보면서 이해하니, 내 코드가 생각보다 많이 복잡했음을 알 수 있었다.
나는 주어진 짝수가 여러 소수의 합으로 나타낼 수 있고, 그게 총 몇 쌍일지를 모르므로 ArrayList 구조를 사용해야 한다고 생각했지만, while문 하나로도 간단하게 코드를 짤 수 있는 문제였다.
<기존 나의 풀이의 개선점>
: 사용하지 않아도 될 변수 + 자료구조가 꽤 많고, 코드가 복잡했다!
import java.io.*;
import java.util.ArrayList; // 사용할 필요가 없었다
public class Main {
public static boolean[] prime = new boolean[10001];
public static int n;
public static ArrayList<Integer> goldberg; // 사용할 필요가 없었다
public static int sub_index; // 사용할 필요가 없었다
public static void main(String[] args) throws IOException {
try { // 사용할 필요가 없었다
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
int T = Integer.parseInt(br.readLine().trim());
get_prime();
for (int i = 0; i < T; i++) {
n = Integer.parseInt(br.readLine().trim());
goldberg = new ArrayList<Integer>(); // 사용할 필요가 없었다
if (n > 10000 | n < 4) {
bw.write("ERROR");
break;
} else {
get_goldberg();
}
}
bw.close();
}catch(IndexOutOfBoundsException e) {
System.out.println(e);
}
}
public static void get_prime() {
prime[0] = true;
prime[1] = true;
for (int i = 2; i <= Math.sqrt(10000); i++) {
for (int j = (i * i); j < prime.length; j += i) {
prime[j] = true;
}
}
}
public static void get_goldberg() throws IOException { // 사용할 필요가 없었음. 이 긴 걸!
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
for (int i=3; i<=(n/2); i+=2) {
if( prime[i]==false && prime[(n-i)]==false) {
goldberg.add(i);
goldberg.add((n-i));
}else if(prime[i]==false && (2*i)==n) {
goldberg.add(i);
goldberg.add(i);
}
}
int min = Integer.MAX_VALUE;
int sub_index = 0;
for (int i = 0; i < goldberg.size(); i += 2) {
int sub = Math.abs(goldberg.get(i) - goldberg.get(i + 1));
if (sub < min) {
sub_index = i;
}
}
bw.write(String.valueOf(goldberg.get(sub_index)) + " ");
bw.write(String.valueOf(goldberg.get(sub_index + 1)) + "\n");
bw.flush();
}
}
<핵심>
1. 한 수의 합이 되는 두 수의 쌍 중 가장 차가 적은 것을 선택하려면, (블로그 글 보면서 배운점)
: 짝수 2N의 경우 N+N에서부터 시작하여, (N-1)+(N+1) 이런 식으로 첫 번째 수는 하나씩 감소, 두 번째 수는 하나씩 증가시킨다. 그러면 두 수의 차가 커지면서 두 수의 합은 그대로 유지된다. 이런 식으로 while문을 전개시키고, 두 수가 모두 소수가 되는 시점에 while문을 break하면 다른 변수를 생성하지 않아도 된다.
2. 주어진 짝수의 범위는 어차피 제한되어 있으니, 처음에 크기가 10001(10000+1)인 boolean 타입의 배열을 만들고 그 범위의 소수를 다 구하는 것이 매번 새로 배열을 만들고 소수를 새로 구하는 것 보다 빠르다. (당연하지만...!)
<코드 다시 작성>
import java.io.*;
public class Main {
public static boolean[] prime = new boolean[10001];
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
int T = Integer.parseInt(br.readLine().trim());
get_prime();
while(T>0) {
int n = Integer.parseInt(br.readLine().trim());
int firstNum = n/2;
int secondNum = n/2;
while(true) {
if(prime[firstNum]==false && prime[secondNum]==false) {
System.out.println(firstNum + " " + secondNum);
break;
}
firstNum--;
secondNum++;
}
T--;
}
bw.close();
}
public static void get_prime() {
prime[0] = true;
prime[1] = true;
for (int i = 2; i <= Math.sqrt(10000); i++) {
for (int j = (i * i); j < prime.length; j += i) {
prime[j] = true;
}
}
}
}
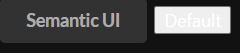
오른쪽이 가장 기본적인 버튼인데, 화려하지 않은 정말 기본 디자인이다. 그런데 button 태그에 class 선택자를 지정했더니 왼쪽 버튼처럼 모양이 바뀐 것을 볼 수 있다.
-> 이는 우리가 link 태그로 불러온 semantic.min.css 파일에 "ui button"이라는 클래스에 할당된 버튼 서식(?)이 따로 존재하기 때문에 가능하다. 파일을 불러오지 않고 class만 지정한다고 바뀌는 게 당연히 아니다.
Q. 버튼을 직접 만드는 건 매우매우 어려울 것 같은데, 여러 버튼 디자인을 사용하고 싶다면 라이브러리를 떠돌아 다니면 되는 것인지 궁금하다.
(A). 후속 강의를 들어 본 결과 그런 것 같다... 하지만 요즘은 여러 UI들이 많이 나와서 그나마 다행. 아마 내가 생각한 것의 대부분은 인터넷 어딘가에 돌아다니지 않을까 싶다.
3. Semantic UI 잘 사용하는 법
1. Semantic UI의 사이드바
: 사이드바에는 Semantic UI로 구현할 수 있는 여러 기능들이 있다. 각 기능을 누르면 해당 기능을 구현하면 어떤 모습이 되는지를 보여준다. 이걸 참고해서 원하는 기능을 사용하면 된다.
2. 원하는 기능을 가져오는 방법
1) Include in your HTML에서 미리 해당 css 파일과 javascript파일을 link 태그로 가져온다.
2) 해당 기능의 Example 코드를 복사 붙여넣기한다.
=> 2)까지 하면 실행되는 기능이 있고, 실행이 안 되는 기능이 있다.
실행이 안 되는 기능의 경우, javascript의 기능이 필요해서 그렇다. 즉 javascript를 initialize(초기화)해야 한다. 3)으로!
* 이런 기능은 보통 '움직임'을 포함하는 경우가 많다!
3) 보통 이런 기능의 경우, 페이지에 4가지의 탭이 있다. (Definition / Examples / Usage / Settings)
여기서 Usage에 들어가서, javascript 코드를 복사해 줘야 한다.
복사할 때는 script 태그 만들고 그 안에 넣어줘야지, 그냥 넣어주면 반영이 안 된다!
b/c html에서 script태그의 역할 중 하나는, css나 javascript등 다른 언어? 프로그램?을 불러올 때 script 태그 안의 코드는 그 다른 언어로 시행하겠다! 라고 선언하는 것이기 때문에, 이 선언을 안 해주면 html이 해당 코드를 javascript 방식으로 처리하지 못한다.
<사용예시>
1. Dropdown
이렇게 Text라고 쓰여진 버튼? 을 누르면 위/아래로 선택할 수 있는 콤보 상자처럼 나오는 기능이 Dropdown이다. 이 기능은 '움직임'이 있어서 그런지 javascript를 initialize해야 사용할 수 있다.
1) 코드 복사하기
2) javascript initialize시키기 : script 태그를 밑에 추가하고, 이런 코드를 추가한다.
<script>
$('.ui.dropdown').dropdown();
</script>
이 코드는 javascript의 문법대로 실행된다.
$ 뒤의 () 안에는 어떤 대상에다 코드를 적용할 것인지를 명시하고, 뒤에는 메소드(함수)를 호출한 것이다.
즉 javascript에 있는 dropdown 함수를 불러와서 class가 ui dropdown인 엘리먼트들에 해당 기능을 적용했다.
3) 기존 기능을 변경하는 방법
: Semantic UI를 사용하면서 원하는 점과 조금 다를 수 있다.
ex) dropdown의 목록이 좀 더 천천히 내려왔으면 좋겠다 등등
-> 그런 세부사항들은 4가지 탭 (Definition / Examples / Usage / Settings) 중에서 Settings에서 설정 가능하다.
이런 식으로 각 기능들이 있다. 가운데는 default value이고, 오른쪽엔 설명, 왼쪽에는 해당 속성의 이름이 나와 있다. 즉 이 속성을 변경하고 싶으면 duration 값을 다르게 바꿔 주면 된다.