회사에서 DB 지식을 좀 쌓기 위해서 그림으로 공부하는 오라클 구조라는 책을 읽는 중이다. 아직 12장 중 4장까지만 읽었고 정독보다는 속독을 하는 중인데, 읽다보니 새삼 내가 DB에 대해서 제대로 아는 게 없다는 사실을 많이 느꼈다. 그래서 포스팅을 통해 현재까지의 내가 뭘 모르고 뭘 아는지를 정리해보려고 한다.
✅ 내용 정리
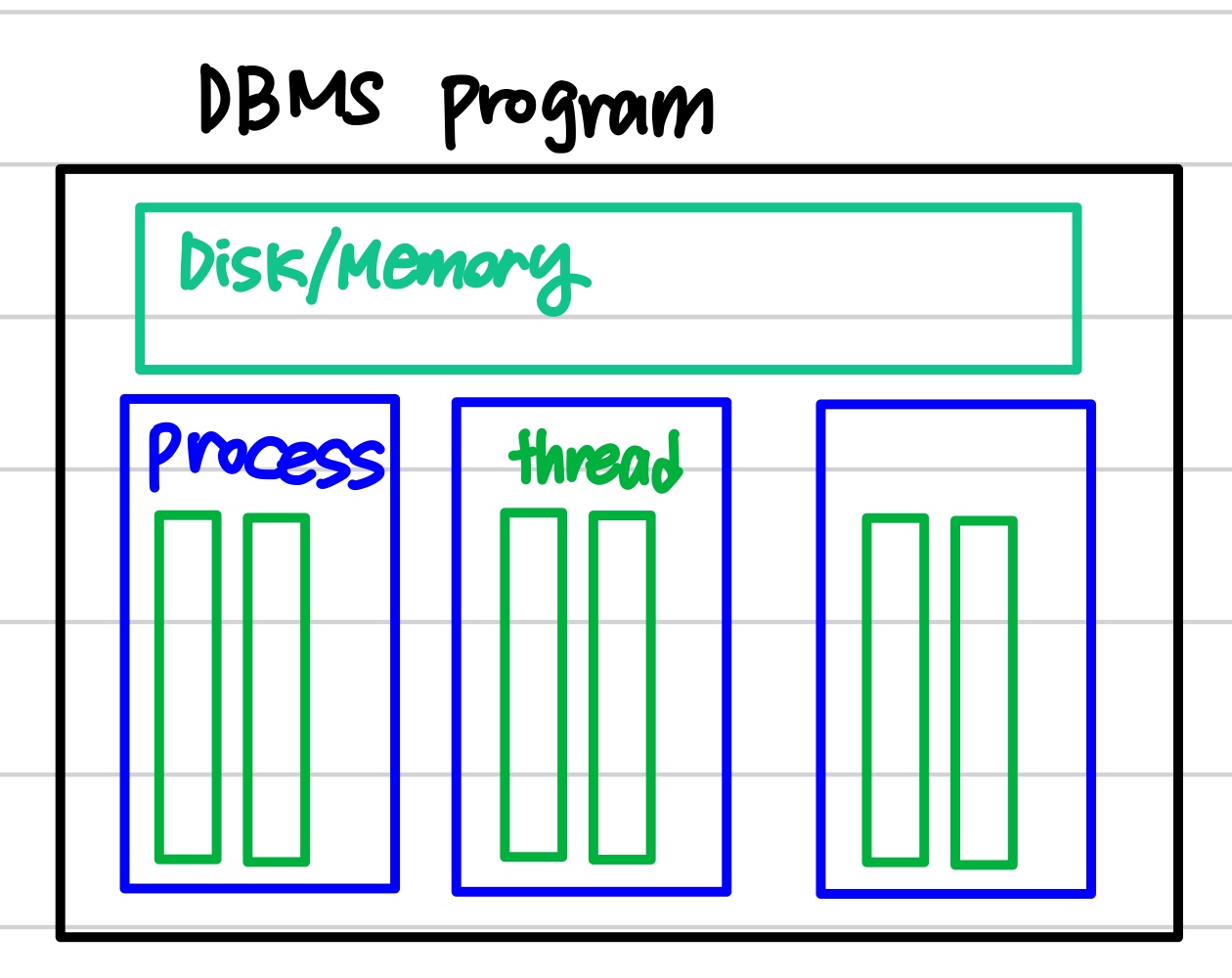
우리가 많이 들어본 Oracle, MySQL, MariaDB, PostgreSQL과 같은 데이터베이스들은 모두 DBMS(database management system)의 여러 종류들이다. DBMS는 데이터를 저장하고 꺼내올 수 있는 디스크나 메모리같은 저장 장치만을 의미하는 것이 아니라, 넓은 의미로는 DB의 4원칙이라 불리는 ACID를 보장할 수 있도록 관리해주는 시스템이라고 이해했다.
내가 이해한 ACID는 다음과 같다.
Atomicity: commit은 원자적이다. 하나의 commit은 전체가 모두 반영되거나 전체가 모두 반영되지 않는다.
Consistency: DB의 데이터는 일관성 있게 관리되어야 한다.
Isolation: 트랜잭션이 다른 트랜잭션의 간섭을 받지 않고 독립적으로 실행되는 것을 보장한다. 여기서 '독립적'이라는 말은 해석의 여지가 있다. 이는 DB의 isolation level에 따라서 다르게 해석될 수 있다.
Durability: commit한 데이터는 어떤 일이 있어도 반드시 DB에 기록되어야 한다.
Durability와 Atomicity를 동시에 보장하는 일은 어렵다고 한다. 특히 Durability를 준수하려면 commit한 데이터는 어떤 일이 있어도 반드시 DB에 기록되어야 한다는 말은 commit 후 DB에 저장하지 않은 상태에서 DB failure가 발생하는 경우를 대비해야 한다.
그러기 위해서 매번 commit 할 때마다 DB에 저장을 하면 되지 않나? 라고 할 수 있지만, 그럴 경우 commit이 빈번하게 되면 DB I/O가 빈번하게 발생하여 성능 저하로 이어진다. 즉 이 ACID를 만족시키면서 동시에 높은 성능을 제공하는 것이 어렵다고 할 수 있다. DBMS는 이 Durability를 지키기 위해서 DB에 데이터를 저장하는 것과 별도로 로그를 기록하는 저장소를 따로 두고 있다고 한다.
Isolation의 경우, DB를 동시에 사용하고 있는 여러 사용자가 있고 그들이 동시에 데이터를 조회하거나 commit을 날릴 경우 어떻게 대응할지에 따라 4단계로 나뉜다. 아래로 갈수록 트랜잭션(transaction)들은 서로 강하게 분리되지만, 그만큼 처리에서 시간이 오래 걸릴 가능성은 높아진다.
Read Uncommited: 어떤 트랜잭션의 변경 내용이 commit과 rollback과 상관없이 다른 트랜잭션에서 보여진다. 예를 들면 A라는 트랜잭션에서 CUD(create/update/delete)하고 commit하지 않은 내용을 다른 트랜잭션에서 조회할 수 있다. 이 경우 Dirty Read 문제가 발생할 수 있다.
Read Committed: 한 트랜잭션이 commit한 내용만 다른 트랜잭션에서 볼 수 있다. 한 트랜잭션에서 commit하지 않고 CUD한 내용들은 Undo 영역에 저장된다고 한다. 그러나 이 경우에도 다른 트랜잭션에서 CUD를 하고 commit을 해 버리면 그 다음부터는 다른 트랜잭션에서 변경된 내역을 바로 볼 수 있기 때문에, Non-Repeatable Read 문제가 발생할 수 있다.
Repeatable Read: 한 트랜잭션이 시작되기 전에 commit된 내용에 대해서만 볼 수 있다. 즉 트랜잭션 여러 개가 진행 중인 상황에서 한 트랜잭션이 commit을 해도 다른 트랜잭션들은 자신이 시작된 시점에 commit 되어있던 내용에 대해서만 볼 수 있다. 이 경우 Non-Repeatable Read는 발생하지 않으나, Insert 문에 대해서는 이야기가 다르다. 다른 트랜잭션에서 Insert 쿼리가 실행되었을 경우 Phantom Read 문제가 생길 수 있다.
Serializable: 하나의 트랜잭션이 실행 중일 때 다른 트랜잭션은 실행되지 않는다. 트랜잭션 간의 실행을 완벽히 분리할 수 있고 Dirty Read, Non-Repeatable Read, Phantom Read 등이 발생하지 않는다는 장점이 있지만, 트랜잭션을 순차적으로 실행하면서 여러 트랜잭션의 처리 시간이 길어지는 단점도 있다.
그리고 Serializable 단계를 제외한 나머지 세 단계에서 나타나는 현상들은 다음과 같다.
Dirty Read: 한 트랜잭션에서 commit 없이 변경한 내용을 다른 트랜잭션에서 읽어들일 수 있다. 만약 이 데이터가 정상적으로 commit되지 않고 rollback 되어도 이미 그 데이터를 읽어들인 다른 트랜잭션에서는 이를 알 길이 없다. 즉 트랜잭션의 입장에서는 지금 자신이 읽어들인 데이터가 정상적으로 commit된 것인지 아닌지도 알 수 없다.
Non-Repeatable Read: 한 트랜잭션에서 데이터 변경 없이 여러 번 조회 쿼리를 날렸을 때 그 결과가 바뀔 수 있다.
Phantom Read: 한 트랜잭션에서 데이터 변경 없이 여러 번 조회 쿼리를 날렸을 때, 기존에 있던 데이터가 변경되지는 않지만 새로운 데이터가 생성된 결과가 나올 수 있다.
표로 나타내면 다음과 같다.
Dirty Read
Non-Repeatable Read
Phantom Read
Read Uncommitted
Yes
Yes
Yes
Read Committed
No
Yes
Yes
Repeatable Read
No
No
Yes
Serializable
No
No
No
그리고 SQL을 파싱(parsing)할 때도 DBMS가 관여하는 부분이 있다. SQL은 어떤 데이터를 읽을지(what)를 기술하는 언어이지 어떻게(how) 읽을지를 알려주지 않는다. SELECT FROM, WHERE, GROUP BY, ORDER BY 등으로 어떤 데이터를 읽어올지만 기술한다. 그렇다면 그 데이터를 '어떻게' 읽을지는 DBMS에서 판단하여야 한다.
어떻게 읽는다는 말이 무슨 의미일까? 그냥 읽으면 되는 게 아닐까?
DBMS에서는 SQL 쿼리를 실행할 때 어떻게 하면 해당 쿼리를 효율적으로 실행할지를 고민한다. (사실 전공에서 배운 기억은 있는데 이 부분은 잘 모른다...) 이를 위해서 SQL 파싱 단계에서 만든 parse tree를 사용하기도 하며, 각 DB table에 대한 통계 자료를 사용하기도 한다.
물론 옵션으로 통계 자료를 수집할지 말지, 수집한다면 어느 시점에 수집할지 등을 정할 수 있다. 예를 들면 DBMS는 특정 column의 average, sum, min, max 등의 값을 수집하고 이 값들을 쿼리 최적화(query optimization) 및 쿼리가 효율적인지 평가(query evaluation)하는 데 사용한다고 알고 있다.
✅ 궁금한 점
Oracle, Mysql, Mariadb와 같은 DBMS들은 어떻게 사용자의 정보를 저장할까?
왜 Durability와 Atomicity를 동시에 보장하는 것이 어려울까?
Durability를 준수하기 위해서 로그 저장소를 따로 두고 I/O를 하면 DB I/O를 하는 것에 비해서 어떤 장점이 있을까? 결국 I/O는 똑같아 보이는데 어떤 이유로 이 방법을 택한 것일까?
이제는 과제를 해보자. 슬라이드 뒤편에 과제 슬라이드를 첨부해 주셨으니 하나씩 읽으면서 해 보자.
✅ 과제 #1: 이해하기
슬라이드를 직접 캡처하기가 애매해서 말로 풀어서 써보겠다.
과제 #1에서는 테이블을 만들 때 '코멘트'를 넣는 작업을 하면 된다. 정확히는 django ORM에서 Model의 verbose_name, Field의 verbose_name 값으로 입력한 값이 필드의 '코멘트'가 되도록 하는 작업이다.
사실 나는 '코멘트'가 뭔지 잘 몰랐다. 블로그 글을 보면서 이해한 바로는 '코멘트'는 SQL(mysql, oracle 등) db에서 제공하는 하나의 기능으로, 필드나 테이블의 의미를 나타내기 위한 기능이라고 한다.
아래는 oracle db에서 코멘트를 추가하는 문법이다.
COMMENT ON TABLE 테이블명 IS '코멘트 내용';
COMMENT ON COLUMN 테이블명.컬럼명 IS '코멘트 내용';
어쨌든, 이를 알았으니 과제를 이해해볼 수 있겠다. 내가 알기로는 기본적으로 django model, field에서 있는 verbose_name 값은 db의 comment와 아무런 관계가 없는 것이 기본값이다.
관계를 만들고 싶다면 아마도 DatabaseSchemaEditor를 사용해야 한다고 이해했다. 과제에서 원하는 것은 verbose_name 속성이 create, update, delete 될 때 db의 comment도 같이 업데이트 되는 것이다. verbose_name 속성은 필드나 테이블의 속성을 수정하는 것이므로 migration의 영역이지 queryset의 영역은 아니다.
그리고 일반 migration에서는 이러한 기능을 제공하지 않는다. 정확히 말하면 migration에서도 SQL.runpython(정확한 명령이 맞나 모르겠다)로 raw SQL을 실행시킬 수 있지만, 이러면 매번 필드나 테이블을 변경할 때마다 raw SQL 쿼리를 짜야 한다. 비효율적이라는 말이겠다.
그러므로 그 밑단에 있는 DatabaseSchemaEditor의 기능을 재정의하거나 일부 수정해서, 다음과 같은 일들을 하게 하면 되겠다.
create table/column 작업 시 verbose_name 속성이 있다면 comment 추가하기
update table/column 작업 시 verbose_name 속성이 수정/삭제되었다면 comment 수정하거나 삭제하기
보려고 했는데 source code가 2000줄이 넘는다... 일단은 문서를 보고 이해가 안 되면 코드를 보자. 다행히 이럴 줄 알았는지 SchemaEditor 문서에는 메소드들이 잘 설명되어 있었다. 여기서 필드나 모델을 생성하는 경우, 지우는 경우(지우려는 field나 table에 comment가 있다면 지워야 하므로), 수정하는 경우에 대한 메소드들만 정리해 보았다.
create_model
delete_model
alter_db_table_comment
add_field
remove_field
alter_field
한 가지 의문은 왜 table의 경우 'alter_db_table_comment' 메소드가 따로 있는데 필드의 경우는 없는지 모르겠다. 정 없으면 alter_field 메소드에서 작업을 대신하면 되니 일단 넘어가자.
그 다음에 할 일은 이 메소드들의 소스 코드만 보고, 작업을 아주 대략적으로 이해하는 것이다. 우선 'create_model' 메소드를 봐 봤다. table_sql이란 다른 메소드를 통해 실행할 SQL을 받아온 다음, 추가적인 작업을 더 하는 것으로 보였다. 그 중에서도 중요한 부분은 db_comment와 관련된 이 부분이었다.
class BaseDatabaseSchemaEditor:
def create_model(self, model):
"""
Create a table and any accompanying indexes or unique constraints for
the given `model`.
"""
sql, params = self.table_sql(model)
# Prevent using [] as params, in the case a literal '%' is used in the
# definition on backends that don't support parametrized DDL.
self.execute(sql, params or None)
if self.connection.features.supports_comments:
# Add table comment.
if model._meta.db_table_comment:
self.alter_db_table_comment(model, None, model._meta.db_table_comment)
# Add column comments.
if not self.connection.features.supports_comments_inline:
for field in model._meta.local_fields:
if field.db_comment:
field_db_params = field.db_parameters(
connection=self.connection
)
field_type = field_db_params["type"]
self.execute(
*self._alter_column_comment_sql(
model, field, field_type, field.db_comment
)
)
# Add any field index (deferred as SQLite _remake_table needs it).
self.deferred_sql.extend(self._model_indexes_sql(model))
# Make M2M tables
for field in model._meta.local_many_to_many:
if field.remote_field.through._meta.auto_created:
self.create_model(field.remote_field.through)
한 메소드만 가져와봤는데도 길다... 암튼 여기서 중요한 부분은 'alter_db_table_comment'와 'if field.db_comment' 부분이다. 이 부분에서는 각각 table comment와 column comment를 더해준다는 주석이 적혀있어서 금방 알아볼 수 있었다.
그럼 이 부분을 override 해 주면 되겠다. 그런데 migration 수정은 해 봤어도 DatabaseSchemaEditor 수정은 처음 해 본다. 이 부분은 잘 모르겠어서 GPT 찬스를 써 봤다.
크게 세 단계를 거치면 되었다.
BaseDatabaseSchemaEditor를 상속받는 새 DatabaseSchemaEditor 클래스를 작성한다.
각 DB(여기서는 SQLite)의 DatabaseWrapper 클래스를 상속받아서 1번에서 정의한 새 SchemaEditor를 사용함을 선언한다.
1번과 2번 파일이 들어있는 모듈을 만들고, 1번은 schema.py에, 2번은 base.py 파일에 위치시킨다.
settings.py의 DATABASES 변수 값 안의 'engine' 속성을 3번의 프로젝트 상대 경로로 지정한다.
그럼 이제 이 방식대로 코딩을 해 보자.
우선 1번, 새 DatabaseSchemaEditor 클래스를 작성해 보자. 관건은 어떻게 하면 '적은 코드를 바꿔서 comment를 수정하도록 할 것인가'였다. 이를 위해서 'comment'로 전체검색을 해 보았다. 그랬더니 다음과 같은 코드가 나오는 게 아닌가.
sql_alter_table_comment = "COMMENT ON TABLE %(table)s IS %(comment)s"
sql_alter_column_comment = "COMMENT ON COLUMN %(table)s.%(column)s IS %(comment)s"
이 변수들을 사용하는 코드를 찾아보았다. alter_table_comment 변수는 alter_db_table_comment에서 사용하고 있었다. 그리고 이 alter_db_table_comment는 create_model 메소드에서 호출되고 있었다. 그렇다면 모델을 만들 때 외에는 comment를 별도로 업데이트하지 않는 것인가? 일단 이 의문을 갖고 넘어가 보자.
def alter_db_table_comment(self, model, old_db_table_comment, new_db_table_comment):
if self.sql_alter_table_comment and self.connection.features.supports_comments:
self.execute(
self.sql_alter_table_comment
% {
"table": self.quote_name(model._meta.db_table),
"comment": self.quote_value(new_db_table_comment or ""),
}
)
이번에는 sql_alter_column_comment 변수의 사용처를 찾아보았다. _alter_column_comment_sql에서 사용되고 있었고, 해당 함수는 create_model, add_field, _alter_column_type_sql 함수에서 사용되고 있었다. _alter_column_type_sql에서 사용된 것은 의외였다. column type을 바꾸는 데 comment가 관여할 여지가 있나 의문이다.
여기서 왜 코멘트 관련 문법이 이렇게 간단하지 싶었는데, 알고보니 코멘트의 create, update, delete 문법이 모두 같았다. 그래서 위의 두 가지 sql문으로 모두 커버가 되는 것이었다. 그러면 이제는 위에서 언급된, comment 관련 필드를 사용하는 메소드를 override 해 주면 되겠다.
create_model
add_field
_alter_column_type_sql
✅ 과제 #1: 결과물
세 개의 메소드를 재정의하였고, 주 변경 내용은 필드를 바꾼 것이었다. 예를 들면 기존의 table._meta.db_comment로 되어있는 변수 대신 table._meta.verbose_name으로 바꿔 주는 작업이 주였다. 구현해 본 코드는 다음과 같다. (구현한 부분에다가만 주석을 달아보았다)
# custom_engine/schema.py
from django.db.backends.mysql.schema import DatabaseSchemaEditor
from django.db.backends.utils import split_identifier
from django.db.models import NOT_PROVIDED
class CustomDatabaseSchemaEditor(DatabaseSchemaEditor):
def create_model(self, model):
"""
Create a table and any accompanying indexes or unique constraints for
the given `model`.
"""
sql, params = self.table_sql(model)
# Prevent using [] as params, in the case a literal '%' is used in the
# definition on backends that don't support parametrized DDL.
self.execute(sql, params or None)
if self.connection.features.supports_comments:
"""
추가한 부분 - 'db_table_comment' 대신 'verbose_name' 사용
"""
if model._meta.verbose_name:
self.alter_db_table_comment(model, None, model._meta.verbose_name)
if model._meta.db_table_comment:
self.alter_db_table_comment(model, None, model._meta.db_table_comment)
"""
추가한 부분 - 'db_table_comment' 대신 'verbose_name' 사용
"""
if not self.connection.features.supports_comments_inline:
for field in model._meta.local_fields:
if field.verbose_name:
field_db_params = field.db_parameters(
connection = self.connection
)
field_type = field_db_params["type"]
self.execute(
*self._alter_column_comment_sql(
model, field, field_type, field.verbose_name
)
)
# Add column comments.
if not self.connection.features.supports_comments_inline:
for field in model._meta.local_fields:
if field.db_comment:
field_db_params = field.db_parameters(
connection=self.connection
)
field_type = field_db_params["type"]
self.execute(
*self._alter_column_comment_sql(
model, field, field_type, field.db_comment
)
)
# Add any field index (deferred as SQLite _remake_table needs it).
self.deferred_sql.extend(self._model_indexes_sql(model))
# Make M2M tables
for field in model._meta.local_many_to_many:
if field.remote_field.through._meta.auto_created:
self.create_model(field.remote_field.through)
def add_field(self, model, field):
"""
Create a field on a model. Usually involves adding a column, but may
involve adding a table instead (for M2M fields).
"""
# Special-case implicit M2M tables
if field.many_to_many and field.remote_field.through._meta.auto_created:
return self.create_model(field.remote_field.through)
# Get the column's definition
definition, params = self.column_sql(model, field, include_default=True)
# It might not actually have a column behind it
if definition is None:
return
if col_type_suffix := field.db_type_suffix(connection=self.connection):
definition += f" {col_type_suffix}"
# Check constraints can go on the column SQL here
db_params = field.db_parameters(connection=self.connection)
if db_params["check"]:
definition += " " + self.sql_check_constraint % db_params
if (
field.remote_field
and self.connection.features.supports_foreign_keys
and field.db_constraint
):
constraint_suffix = "_fk_%(to_table)s_%(to_column)s"
# Add FK constraint inline, if supported.
if self.sql_create_column_inline_fk:
to_table = field.remote_field.model._meta.db_table
to_column = field.remote_field.model._meta.get_field(
field.remote_field.field_name
).column
namespace, _ = split_identifier(model._meta.db_table)
definition += " " + self.sql_create_column_inline_fk % {
"name": self._fk_constraint_name(model, field, constraint_suffix),
"namespace": (
"%s." % self.quote_name(namespace) if namespace else ""
),
"column": self.quote_name(field.column),
"to_table": self.quote_name(to_table),
"to_column": self.quote_name(to_column),
"deferrable": self.connection.ops.deferrable_sql(),
}
# Otherwise, add FK constraints later.
else:
self.deferred_sql.append(
self._create_fk_sql(model, field, constraint_suffix)
)
# Build the SQL and run it
sql = self.sql_create_column % {
"table": self.quote_name(model._meta.db_table),
"column": self.quote_name(field.column),
"definition": definition,
}
# Prevent using [] as params, in the case a literal '%' is used in the
# definition on backends that don't support parametrized DDL.
self.execute(sql, params or None)
# Drop the default if we need to
if (
field.db_default is NOT_PROVIDED
and not self.skip_default_on_alter(field)
and self.effective_default(field) is not None
):
changes_sql, params = self._alter_column_default_sql(
model, None, field, drop=True
)
sql = self.sql_alter_column % {
"table": self.quote_name(model._meta.db_table),
"changes": changes_sql,
}
self.execute(sql, params)
"""
추가한 부분 - 'db_table_comment' 대신 'verbose_name' 사용
"""
if (
field.verbose_name
and self.connection.features.supports_comments
and not self.connection.features.supports_comments_inline
):
field_type = db_params["type"]
self.execute(
*self._alter_column_comment_sql(
model, field, field_type, field.verbose_name
)
)
# Add field comment, if required.
if (
field.db_comment
and self.connection.features.supports_comments
and not self.connection.features.supports_comments_inline
):
field_type = db_params["type"]
self.execute(
*self._alter_column_comment_sql(
model, field, field_type, field.db_comment
)
)
# Add an index, if required
self.deferred_sql.extend(self._field_indexes_sql(model, field))
# Reset connection if required
if self.connection.features.connection_persists_old_columns:
self.connection.close()
def _alter_column_type_sql(
self, model, old_field, new_field, new_type, old_collation, new_collation
):
"""
Hook to specialize column type alteration for different backends,
for cases when a creation type is different to an alteration type
(e.g. SERIAL in PostgreSQL, PostGIS fields).
Return a 2-tuple of: an SQL fragment of (sql, params) to insert into
an ALTER TABLE statement and a list of extra (sql, params) tuples to
run once the field is altered.
"""
other_actions = []
if collate_sql := self._collate_sql(
new_collation, old_collation, model._meta.db_table
):
collate_sql = f" {collate_sql}"
else:
collate_sql = ""
"""
추가한 부분 - 'db_table_comment' 대신 'verbose_name' 사용
"""
comment_sql = ""
if self.connection.features.supports_comments and not new_field.many_to_many:
if old_field.verbose_name != new_field.verbose_name:
sql, params = self._alter_column_comment_sql(
model, new_field, new_type, new_field.verbose_name
)
if sql:
other_actions.append((sql, params))
# Comment change?
if self.connection.features.supports_comments and not new_field.many_to_many:
comment_sql = ""
if old_field.db_comment != new_field.db_comment:
# PostgreSQL and Oracle can't execute 'ALTER COLUMN ...' and
# 'COMMENT ON ...' at the same time.
sql, params = self._alter_column_comment_sql(
model, new_field, new_type, new_field.db_comment
)
if sql:
other_actions.append((sql, params))
if new_field.db_comment:
comment_sql = self._comment_sql(new_field.db_comment)
return (
(
self.sql_alter_column_type
% {
"column": self.quote_name(new_field.column),
"type": new_type,
"collation": collate_sql,
"comment": comment_sql,
},
[],
),
other_actions,
)
이렇게 구현해 보고, 2번 과정인 DatabaseWrapper 클래스를 선언해 주었다.
# custom_engine/base.py
from custom_engine.schema import CustomDatabaseSchemaEditor
from django.db.backends.sqlite3.base import DatabaseWrapper as SQLite3DatabaseWrapper
class CustomSQLite3DatabaseWrapper(SQLite3DatabaseWrapper):
SchemaEditorClass = CustomDatabaseSchemaEditor
# custom_engine/base.py
from django.db.backends.mysql.base import DatabaseWrapper
from .schema import CustomDatabaseSchemaEditor
class CustomMysqlDatabaseWrapper(DatabaseWrapper):
SchemaEditorClass = CustomDatabaseSchemaEditor
무슨 일일까. 우선 아래의 명령어를 사용하면 table에 생성된 comment를 볼 수 있다고 해서 그대로 따라해 보았다.
SELECT
table_name, table_comment
FROM
information_schema.tables
WHERE
table_schema = 'DB 이름' AND table_name = '테이블 이름';
왜 없을까 생각해보니 짚이는 점은 두 가지였다.
custom backend가 제대로 동작(호출)되지 않았다.
custom backend의 코드가 잘못되었다.
우선 1번의 가능성을 보기 위해서 새 모델에 임의의 필드를 추가하여 마이그레이션을 해보고, 그 상황에서 해당 custom backend의 코드가 호출되었는지를 디버거 등으로 살펴봐야 하겠다.
우선 myapp의 모델에서 변경 사항이 실행될 수 있도록 마이그레이션을 되돌려 보자(revert migrations). 해당 명령어를 실행하니 마이그레이션이 잘 되돌려졌다.
python manage.py migrate myapp 0004
마이그레이션을 한 단계 이전으로 되돌렸다. 이제는 다시 migrate 명령어를 실행해서 revert했다가 다시 실행하려는 그 migration이 잘 되는지를 테스트 할 차례인데, 그 전에 우선 custom backend에서 verbose_name 관련해서 새로 작성한 코드들에 전부 breakpoint를 걸어놓았다.
디버깅을 하다 보니 이상한 점이 있었다. custom_engine 디렉토리의 base.py 파일까지는 breakpoint에 걸리는데, 그 안에서 'SchemaEditorClass' 변수 값으로 정의한 CustomDatabaseSchemaEditor 클래스의 세부 메소드는 breakpoint에 걸리지 않았다. 이유가 무엇일까? 일단은 위에서 짚이는 방법 중 1번 원인이 유력해 보였다. 코드가 잘못된 게 아니라 호출되지 않아서 반영되지 않은 것 같았다. 하지만 왜일까.
다른 방법으로 현재 모듈에서 backend engine으로 위에서 정의해 준 backend wrapper를 사용하고 있는지를 알아보았다.
python manage.py shell
from django.db import connection
print(type(connection))
with connection.schema_editor() as editor:
print(type(editor))
그랬더니 이런 결과가 나왔다. 즉 CustomDatabaseSchemaEditor 클래스가 사용되지 않고 있었다. 이유가 무엇일까?
일단 여기서 막힌 상태이다. 좀 더 이유를 찾아봐야겠다...!!
✅ 과제 #1: 궁금한 점
왜 table에서 사용할 수 있는 'alter_db_table_comment' 메소드는 있는데 field에서 사용할 수 있는 전용 메소드를 따로 만들어 주지 않고 다른 방식으로 사용했을까?
DatabaseWrapper는 왜 필요할까? Django는 왜 SchemaEditor를 그대로 사용하는 대신 DatabaseWrapper에 한번 더 감싸는 구조를 사용했을까?
지난 달 11월 9일에 Django ORM 톺아보기 세션이 열렸어서 가서 재밌고 유익하게 들었었다. ORM을 쓰는 방법은 그래도 대강은 알고 있다고 생각했는데, 쓰는 방법 말고 동작 원리에 대해서는 모르는 부분이 많았다. 특히 Queryset보다 더 밑단의 동작 원리(SQLCompiler, SQL과 QueySet 사이의 계층)에 대해서는 거의 처음 들어봤다. 역시 배워도 배워도 새롭고 신기한 것들 투성이였다.
다행히 슬라이드는 계속 열어 두신다고 하셔서 지금이라도 슬라이드를 훑어보면서 그때의 기억을 되살려 보았다. 예전에 듣기로는 학습을 하는 좋은 방법 중 하나는 내용을 보면서 무엇을 어떻게 이해했고, 무엇을 모르겠는지를 스스로 점검하는 거라고 했다. 오늘 그걸 해 볼 예정이다. 그러면서 과제도 해 보고, 궁금한 것들을 정리해 보려고 한다.
✅ 흐름 이해
ORM의 정의에 대해서 간단히 다룬 뒤, 처음에는 간단한 유저 모델을 생성하고 유저를 조회하는 API를 만들고 이를 실행시켜 보면서 튜토리얼이 진행되었다. 이후 DDL과 DML을 다루면서 Django에서 ORM이 동작하는 대표적인 두 경우를 봤다.
첫 번째는 DDL(data definition language)으로 ORM을 통해 migration을 쓰는 경우였다. 이 경우는 데이터를 CRUD하는 것이 아니라, 테이블 스키마 자체를 정의하고 바꾸는 작업이다. 두 번째는 DML(data manipulation language)로 ORM을 통해 queryset을 쓰는 경우였다. 데이터를 CRUD하는 경우 쿼리셋이 실행된다고 이해했다.
내가 아는 것은 여기까지였다. 그리고 첫 번째와 두 번째 경우에서, migration과 queryset 아래에 또 동작하는 django의 계층이 있음을 새롭게 알았다.
migration의 경우는 migration과 SQL 사이에 DatabaseSchemaEditor 클래스가 동작해서 python 언어로 쓰여진 migration 파일을 SQL로 바꿔 준다고 이해했다. (사실 깊게 파 보면 그게 다가 아니긴 할 것이다. 일단은 넘어가자!) queryset의 경우는 queryset과 SQL 사이에 SQLCompiler 클래스가 동작해서, python 언어로 쓰여진 queryset 조회 코드를 SQL로 바꿔 준다고 이해했다.
그리고 나는 migration과 queryset이 django ORM하면 거론되는 대표적인 기능들이라서 그 밑단에서는 정보가 많이 없을 것이라고 생각했었는데, DatabaseSchemaEditor 공식 문서가 있었다. SQLCompiler는 'django sql compiler'로 검색했을 때는 정보가 안 나왔는데, 분명 다른 이름으로 뭔가 있을 것이라는 추측을 해 본다.
공식문서 피셜, (Database)SchemaEditor는 db를 추상화하는 계층이란다. 그리고 django에서 지원하는 모든 database backend 별로 SchemaEditor가 있고, 그 모든 SchemaEditor 클래스들은 BaseDatabaseSchemaEditor를 상속받는다고 한다.
다른 부분은 그래도 잘 읽혔는데, 아래 부분은 잘 안 읽혔다. 'context manager와 같이 사용해야만 transaction, foreign key constraint 등의 상황에서 사용할 수 있으니, context manager와 같이 사용되어야 한다'는 말이었다. 잘 모르겠어서 GPT에게도 물어봤다.
'왜 context manager가 transaction과 deferred SQL(외래키 관련 migration 등이 있을 때, 해당 SQL을 지연시키는 것)을 지원하는지, 이 context manager는 또 뭔지'가 궁금했었다. GPT 녀석은 질문의 의도를 잘 캐치하고 context manager가 무슨 역할을 하는지를 설명해 주었다. 그런데도 모호한 부분이 있어서, context manager에 대해 질문했다.
알고보니 context manager라는 녀석은 django가 아니라 python 자체에서 지원하는 기능이었다. 설명을 보고선 'with statement와 같이 쓰이는 많은 공통 과제들을 좀 더 편리하게 선언/처리할 수 있게 도와주는 util 함수' 라고 이해했다. 그런데 나는 with statement도 사실 잘 몰랐다(어떻게 쓰는지는 아는데 그게 구체적으로 어떨 때 쓰고, 어떤 원리로 동작하는지는 몰랐다).
그래서 조금 삼천포로 빠진 것 같지만 with statement의 정의와 대략적인 동작 원리까지만 찾아보기로 했다. 공식문서를 찾아보니 더 구체적인 정의가 나왔다. with statement로 코드를 실행할 때, 어떤 runtime context를 사용할 것인지를 정의하는 객체가 context manager라고 했다.
context manager는 with문이 실행되는 상황에서 context에 진입하고 종료할 때 부가적인 작업을 해 준다고 이해했다. 즉 with 구문은 일종의 문법이고, 그 문법을 사용해서 코드를 실행할 때는 해당 runtime context의 진입과 종료 작업을 관리하기 위해 context manager가 개입한다고 이해했다. 휴 복잡하다.
암튼 context manager를 이렇게 이해하면 위에서의 말도 이해할 수 있겠다. DatabaseSchemaEditor가 사용되는 raw django code에서는 with문으로 deferred SQL이나 transaction을 처리하는 부분이 있나보다. 그래서 context manager와 같이 사용해야 한다는 설명을 덧붙인 것이겠다.
WS는 정적인 컨텐츠에 대한 요청을 처리하며, WAS는 웹 어플리케이션 로직을 통해 동적인 요청을 처리할 수 있다는 점이 가장 큰 차이이다. 그러나 요즘은 WS도 설정하기에 따라 꼭 정적 컨텐츠에 대한 요청만 처리하는 것은 아니라고 해서... 무 자르듯이 아주 정교하게 구분하기는 어렵다고 한다. 또한 예전 멘토링에서 말씀하신 것처럼 WAS 안에 WS가 있는 구조라고 한다. WS는 예를 들면 apache, nginx 등이 있고, WAS는 사용하는 프레임워크 별로 다양하다. 가령 django WAS, tomcat 등이 있다.
✅그러면 WAS만 사용하면 되는 게 아닌가? 굳이 정적인 요청만 처리할 수 있는 WS는 왜 사용할까
요청별로 처리하는 데 드는 비용이 다르다. 가령 주문과 결제 로직을 사용하는 요청의 경우 처리하는 데 드는 시간과 드는 리소스가 더 크고, 반면 단순 이미지를 요청하는 경우는 리소스가 더 작다. 그런데 이 모든 요청을 WAS에게 요청할 경우 값싼 요청을 처리하는 데에도 똑같이 WAS의 리소스를 할당해야 하기 때문에, 이 경우 요청을 먼저 WS가 처리하게 하여서 정적 컨텐츠 요청의 경우는 WAS의 리소스를 아예 사용하지 않도록 할 수 있다.
✅WAS는 어떤 기능을 제공하는가
WAS의 큰 장점 중 하나는 서블릿을 지원한다는 것이다. 서블릿을 사용하게 되면 개발자는 비즈니스 로직에만 더 집중할 수 있다. 서블릿에서는 가령 요청이 들어왔을 때 그 요청에서 헤더를 분리하고, 요청의 경로를 확인하고, 파라미터들을 일일이 다 파싱하고... 등등의 작업을 해 준다. 만약 서블릿이 없다면 개발자는 비즈니스 로직 외에도 위의 작업에 필요한 로직을 다 만들어야 했을 것이다. 이럴 경우 작업 효율성이 떨어지고, 코드도 훨씬 더 복잡해졌을 수 있다.
WAS에서는 서블릿을 지원한다. 요청이 오면 서블릿에서 그 요청을 먼저 처리해서, 위에서 언급한 url 경로를 확인하거나 파라미터 및 헤더를 파싱하는 등의 공통적이고 반복적인 작업을 먼저 처리한다. 그 다음 요청이나 응답을 뷰(MVC 패턴을 쓰는 경우)에서 처리하기 쉽게 요청 및 응답 객체를 새로 생성하여 리턴해 준다. 이는 모든 웹 서버 프레임워크에서 공통적인 것으로 보인다. 지금까지 주로 사용해온 django의 경우도 마찬가지로, view 함수에서는 항상 request 라는 객체를 받았고, 그 안에서 request.headers 등의 기본으로 제공되는 메소드를 통해 요청의 헤더나 파라미터 값들을 쉽게 확인할 수 있었다.
또한 WAS는 멀티스레딩 기능도 제공한다. 싱글 스레드로 클라이언트의 요청을 처리하게 될 경우, 앞선 요청이 지연되는 경우 뒤의 요청들까지 전부 밀리게 된다. 그렇다고 해서 요청이 들어올 때마다 스레드를 생성하게 된다면 스레드를 생성하는 비용이 비싸고, 그렇게 만든 스레드를 재사용할 수 없어서 비효율적이며, 스레드 간 context switching 비용이 발생하며, 요청을 무한대로 제한 없이 받을 수 있어 과도한 요청이 들어오면 WAS가 다운될 수 있다는 단점이 있다. 그래서 보통은 스레드 여러 개를 모아 둔 스레드 풀을 만들어 두고, 요청이 들어오면 스레드 풀에서 필요한 스레드를 꺼내 쓰는 방식으로 사용한다.
✅ 궁금한 점들
❓ django WAS는 다른 WAS와는 어떻게 다를까. 서블릿은 어떻게 구현되어 있는지, 또 멀티스레딩은 파이썬에서 어떻게 구현했을지 궁금하다.
❓ 톰캣에서 사용하는 스레드 풀의 기본 max thread 값은 200개라는데, 현재 개발하고 있는 서비스(onestep)의 경우는 그렇게 많은 스레드가 필요해 보이지는 않는다. 얼마 정도가 적당할지 궁금한데, 아마도 테스트를 통해서 알 수 있을 것 같다. 그러니 테스트도 해 보자.
프로그램을 진행하면서 새 맥북을 받았다! 너무 기뻤지만, 항상 사용하던 윈도우 노트북에서 새 맥북으로 바꾸려니 초기 설정부터 다시 해야 한다는 문제점이 있었다.
혹시라도 내가 다음에 또 노트북을 바꾸게 되거나, 비슷한 개발자들이 있다면 참고할 수 있도록 하기 위해서 간략하게나마 글을 적어본다.
✅설치할 프로그램들
1. brew
이 사이트에서 homebrew를 설치할 수 있다. 나는 homebrew는 mac에서 사용하는 일종의 패키지라고 알고 있고, 실제로 앞으로 설치할 많은 프로그램들(git, docker 등)이 brew install ___으로 간단히 설치가 가능하므로, 맥 사용자라면 homebrew 설치는 거의 필수적이라고 볼 수 있다.
필수 사항은 아니지만, 맥에서 기본으로 제공하는 터미널이 예쁘지 않다는 의견이 많아서 내 주변 맥 사용자들도 다 iterm을 사용하는 것 같아서 깔아봤다. 공식 사이트에서 설치할 수 있다.
5. python
지금 개발중인 프로젝트에서는 python, django를 사용하므로 파이썬도 깔아줬다. 공식 홈페이지에서 맞는 버전을 사용하면 된다.
6. java
지금 개발에서 사용하는 언어는 아니지만, 앱 개발을 하려면 android studio가 필요하고 android studio에서는 java를 필요로 하기 때문에 결론적으로 java도 필요했다. 주의할 점은, java를 설치하는 방법이 꽤나 여러가지라는 것이다. 그리고 android studio에서 빌드를 실행시키다 보면 jdk와 gradle의 버전이 맞지 않아서 나는 오류가 있다.
이 사이트에서는 여러 자바 버전을 설치할 수가 있어서 여러 블로그들을 찾아보다 이 사이트에서 특정 jdk 버전을 다운받아서 오류를 해결하였다.
자바가 잘 설치되었는지 확인하는 명령어는 다음과 같은데, 당연하게도 처음에 이 명령어를 입력하면 java, javac를 인식하지 못한다.
java -version
javac -version
그 이유는 java에 대해서 환경변수 등록을 해주지 않았기 때문이다.
맥에서는 루트 폴더 기준으로 .zshrc 라는 파일에 여러 환경변수 경로를 설정할 수 있는데, 이 안에 다음과 같이 입력해 주자.
참고로 맥에서 파일을 읽거나 쓰기 위해서는 vim 이나 nano 명령어를 사용한다. 그러니까 iterm의 초기 디렉토리에서 다음과 같이 입력하면 아마도 .zshrc 창이 열릴 거다.
vim .zshrc
여기서 -v 다음에 있는 17의 경우, 나의 경우는 jdk 17을 사용하고 싶어서 제한을 둔 것이다. 만약 다른 버전의 jdk를 명시적으로 사용하고 싶다면 17 대신 다른 숫자를 입력하면 된다.
인증 백엔드는 세션과도 연관이 있다. 하나의 세션에서는 인증에 사용하는 백엔드를 캐싱해 두고 인증할 때 그 클래스를 사용한다.
django.contrib.auth 모듈의 authenticate()를 호출하면 장고의 모든 인증 백엔드에서 순차적으로 인증을 시도한다.
☑️login() vs authenticate()
인증을 수행한다는 공통점이 있다.
authenticate(): 인증 정보가 유효한지를 한 번 확인한다.
login(): 인증 정보가 유효한지를 확인하고 유효하다면 세션을 만드는 등의 후처리를 한다. 그 결과 한 번 인증된 유저를 여러 번 인증할 필요가 없게 한다.
✅Custom Authentication
기본 인증을 사용하지 않고 새로운 인증 클래스를 만들어서 사용해야 할 때도 있다.
예를 들면 서로 다른 두 앱(django app)의 유저를 통합하거나 할 때, 두 앱에서 모두 사용할 수 있는 인증 클래스가 필요할 것이다.
새로운 인증 백엔드 클래스(Authentication Backend)를 만들기 위해서는 크게 두 가지가 필요하다.
django.contrib.auth.backends 모듈의 BaseBackend 클래스를 상속하는 새 클래스 만들기
해당 클래스에서 두 가지 메소드 구현하기
authenticate: 요청 및 필요시 추가 정보(credentials)를 받아서 인증 되면 user, 아니면 None을 리턴한다.
get_user: user 인스턴스의 pk 값을 받아서 user를 리턴한다.
from django.contrib.auth.backends import BaseBackend
class CustomBackend(BaseBackend):
def authenticate(self, request, credentials=None):
...
def get_user(self, user_id):
...
...
✅Authentication Backend에서 권한(Permissions) 부여하기
BaseBackend 클래스에서는 User 모델 및 UserManager 클래스에서 정의하는 여러 권한 조회 함수들(permission lookup functions)을 사용할 수 있다.
get_user_permissions: 해당 유저가 직접적으로 가진 권한들을 리턴한다.
get_group_permissions: 해당 유저가 속한 그룹이 가진 권한들을 리턴한다.
get_all_permissions: 위의 두 메소드의 합집합을 리턴한다.
has_perm(perm): 유저가 해당 권한을 가지고 있는지를 boolean 값으로 리턴한다.
has_module_perms(module_name): 유저가 해당 모듈(django app)에 해당하는 권한을 하나라도 갖고 있다면 True를 리턴한다.
만약 시행 중 Permission Denied 에러가 리턴되면, 미들웨어처럼 이후의 인증 백엔드를 거치지 않고 에러를 리턴한다.
✅특정 모델 인스턴스에 대해 권한 생성하기
모델 클래스의 Meta 옵션에 permissions 속성을 추가하고, 그 값으로 추가하고 싶은 권한들을 작성한다.
권한들도 DB를 사용하는 경우 하나의 테이블로 맵핑되기 때문에, 이렇게 추가한 권한 값들은 migrate 명령어를 실행한 이후에 생성되므로 그 이후에 사용할 수 있다.
class Task(models.Model):
...
class Meta:
permissions = [
("change_task_status", "Can change the status of tasks"),
("close_task", "Can close the status of tasks"),
]