이 포스트는 인프런의 스프링부트 시큐리티 강의를 참고하여 작성되었습니다.
✅프로젝트 구조
구글 로그인은 소셜로그인의 일종이기 때문에 스프링 시큐리티를 사용할 때 OAuth와 함께 사용해야 한다. 홈페이지에서는 일반 로그인과 구글로그인을 같이 구현하는 것이 목표이므로, 일반 로그인의 코드를 따로 건드리지 않고 구글 로그인 코드를 작성해 주어야 하겠다.
일반 로그인 관련 코드는 auth라는 패키지에, 소셜 로그인 관련 코드는 oauth 패키지에 따로 묶어두자.
스프링 시큐리티를 사용할 때 가장 기본이 되는 클래스는 SecurityConfig 클래스다. 이 클래스 내부에는 SecurityFilterChain 인스턴스를 리턴하는 filterChain() 메소드가 재정의된다. filterChain() 메소드는 스프링 시큐리티가 개입할 때 가장 먼저 호출되는 메소드이다.
이 클래스에 @EnableWebSecurity 어노테이션을 붙여서 내부에 정의된 filterChain() 메소드를 스프링 필터체인(filterChain)에 등록한다.
@Configuration
@EnableWebSecurity
@EnableMethodSecurity(securedEnabled = true)
public class SecurityConfig {
@Autowired
public PrincipalOauth2UserService principalOauth2UserService;
@Bean
public BCryptPasswordEncoder encoder(){
return new BCryptPasswordEncoder();
}
@Bean
public SecurityFilterChain filterChain(HttpSecurity http) throws Exception {
http.csrf(csrf -> csrf.disable());
http
.cors(cors -> cors.disable())
.csrf(csrf -> csrf.disable())
.authorizeHttpRequests((authz) -> authz
.requestMatchers("/login", "/loginForm", "/loginProc", "/join", "/joinProc", "/user").permitAll()
.anyRequest().authenticated()
)
.formLogin((formLogin) ->
formLogin
.loginPage("/loginForm")
.loginProcessingUrl("/loginProc")
.defaultSuccessUrl("/"))
.oauth2Login((oauth2Login) ->
oauth2Login
.loginPage("/loginForm")
.userInfoEndpoint(userInfoEndpointConfig -> userInfoEndpointConfig.userService(principalOauth2UserService))
)
.httpBasic(withDefaults());
return http.build();
}
}
HttpSecurity.cors(), HttpSecurity.csrf()의 내부에서는 CORS, CSRF 처리를 어떻게 할지를 정의할 수 있다.
HttpSecurity.authorizeHttpRequests() 내부에서는 프로젝트의 각 엔드포인트에 대해 접근권한을 허용할지 말지를 결정할 수 있다. requestMatchers() 안에 url 패턴을 선언해서 해당 패턴들을 가진 엔드포인트들을 한 번에 처리할 수도 있다.
뒤에 authenticated()를 붙이면 해당 엔드포인트들에 대해서는 인증을 실행하고, permitAll()을 붙이면 해당 엔드포인트에 대한 요청들은 별도의 인증을 안 하고 통과시킨다.
HttpSecurity.formLogin() 내부에서는 시큐리티 기본 로그인을 어떻게 할지를 설정한다. 기본 로그인이란 아이디, 비밀번호를 입력해서 사용자를 인증하는 로그인이다. 메소드 내부에서는 .loginPage()로 어떤 엔드포인트를 기본 로그인 페이지로 설정할지를 정할 수 있다. 이 경우 인증되지 않은 사용자가 인증이 필요한 페이지를 요청할 경우 기본 로그인 페이지로 리다이렉트 된다.
.loginProcessingUrl()은 로그인 과정을 처리하는 엔드포인트다. 보통 로그인 폼에서 '로그인'을 눌렀을 때 로그인 과정을 처리하는 엔드포인트로 이동하고, 해당 엔드포인트에서 로그인 인증이 진행된다.
.defaultSuccessUrl()은 로그인이 성공했을 때 리다이렉트 될 엔드포인트이다.
HttpSecurity.oauth2Login() 내부에서는 OAuth 로그인을 어떻게 설정할지를 작성한다. .loginPage()에서 설정한 엔드포인트로부터 들어오는 요청들에 대해서 oauth provider(구글, 네이버 등등)가 인증을 진행한다. 로그인 페이지 말고도 여러 엔드포인트를 설정할 수 있다.
그 전에, OAuth에서는 3가지의 주체가 있다: Client, Resource Owner, Resource Server
client는 소셜로그인을 이용하려는 웹사이트의 서버, resource owner는 사용자, resource server는 구글 등 소셜로그인 서비스를 제공하는 서버이다.
✅스프링 시큐리티 OAuth 2.0에서 지정한 엔드포인트(protocol endpoint)
1. Authorization Endpoint
client가 resource owner로부터 권한(authorization)을 획득하는 부분이다.
즉 사용자(resource owner)의 로그인이 진행되는 부분이다. 사용자가 로그인을 진행하면 그 과정에서 앱 서비스(client)는 권한 코드(authorization code)를 얻을 수 있다. 사용자의 로그인이 성공적이었다면 1번에서 권한 코드를 얻을 수 있다.
2. Token Endpoint
1번에서 얻은 권한 코드를 액세스 토큰으로 교환하는 지점이다.
3. Redirection Endpoint
인증 서버(resource server)가 앱 서비스(클라이언트)에게 권한 정보(authorization)를 리턴하는 지점이다.
4. UserInfo Endpoint
클라이언트가 인증된 사용자의 정보(claims)를 받기 위해서는 이 엔드포인트로 요청하면 된다.
코드에서는 .userInfoEndpoint()로 사용자의 인증 정보를 받아서 어떻게 처리할지를 설정했다.
.userInfoEndpoint().userService() 에서는 사용자의 인증 정보를 엔드포인트로 받아서 어떤 UserDetailsService 클래스에 넘겨줄지를 설정한다. 여기서는 앞에서 미리 작성한 principalOauth2UserService 클래스에게 유저 정보를 넘겨주기로 설정했다.
✅OAuth 서비스 클래스 작성 - 기존 로그인 로직과 연동
principalOauth2UserService 클래스는 DefaultOAuth2UserService 클래스를 상속하고, DefaultOAuth2UserService 클래스는 OAuth2Service 인터페이스를 구현한다.
OAuth2Service 인터페이스는 UserInfo Endpoint에서 유저 정보를 얻은 뒤 그에 맞는 OAuth2User 인터페이스 타입의 인스턴스를 리턴한다. 즉 우리 클래스는 이 인터페이스를 구현받은 클래스를 상속받고 있으므로 OAuth2Service 인터페이스의 역할 + a를 한다고 볼 수 있다.
해당 클래스는 앞서 구현 및 상속받은 인터페이스, 클래스가 있기 때문에 loadUser() 라는 메소드를 재정의해야 한다. loadUser() 메소드는 UserInfo Endpoint에서 유저 정보를 얻은 뒤 그에 맞는 OAuth2User 인터페이스 타입의 인스턴스를 리턴한다. 인터페이스 타입을 리턴할 수는 없으므로, OAuth2User 인터페이스를 구현한 클래스를 하나 만든 뒤 그 클래스 타입의 인스턴스를 리턴시켜야 하겠다.
(예시 코드)
@Service
public class PrincipalOauth2UserService extends DefaultOAuth2UserService {
@Override
public OAuth2User loadUser(OAuth2UserRequest userRequest) throws OAuth2AuthenticationException {
OAuth2User oauth2User = super.loadUser(userRequest);
// code
return new PrincipalDetails(userEntity, oauth2User.getAttributes());
}
}
여기서 PrincipalDetails라는 클래스는 강의에서 정의한 클래스로, 기존 로그인에서 필요했던 UserDetails 인터페이스와, loadUser()의 리턴 타입인 OAuth2User 인터페이스를 구현한 클래스이다.
앞서 기본 로그인을 진행하기 위해서는 PrincipalOauth2UserService와 같은 역할을 하는 서비스 클래스로 PrincipalDetailsService 클래스를 정의했었고, 해당 클래스는 UserDetailsService 라는 인터페이스를 구현하고 있었다. UserDetailsService 인터페이스에서는 loadUserByUsername() 메소드를 오버라이딩 해야 했는데, 이 메소드의 리턴 타입이 UserDetails 이었다.
즉 PrincipalDetailsService와 PrincipalOauth2UserService의 관계는 매우 비슷하다. 각각 UserDetailsService와 OAuth2Service 인터페이스를 구현하고, 그 인터페이스에 선언된 메소드에서는 각각 UserDetails와 OAuth2User 인터페이스 타입을 리턴한다.
그러므로 PrincipalDetails 클래스에서 두 인터페이스(UserDetails, OAuth2User)를 모두 구현해버리면 하나의 클래스가 일반 로그인 서비스인 PrincipalDetailsService와 소셜로그인 서비스인 PrincipalOAuth2UserService 모두에서 쓰일 수 있게 된다.
대신 일반 로그인과 소셜로그인의 처리 절차가 다를 수 있으므로, UserDetailsService의 loadUserByUsername() 메소드와 OAuth2UserService의 loadUser() 메소드를 각각 다르게 오버라이딩 해 주면 같은 엔드포인트와 같은 클래스 타입을 사용해서 두 가지의 로그인을 한번에 진행할 수 있다.
✅구조 설명
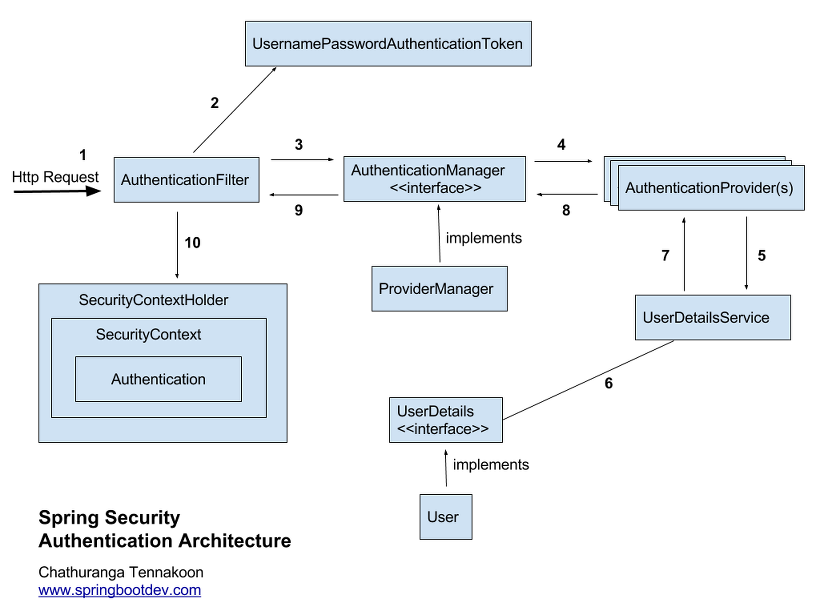
해당 그림은 스프링 시큐리티 구조를 간단히 나타낸 것이다.
앞서 언급한 PrincipalOauth2UserService와 PrincipalDetailsService는 그림에서 'UserDetailsService' 부분에 해당한다. 이 클래스들은 AuthenticationProvider에서 authentication 객체를 건네받은 뒤, 해당 객체를 통해 UserDetails 인터페이스에 접근해서 유저 정보를 가져온 뒤 다시 AuthenticationProvider에게 그 정보를 리턴하는 역할을 한다.
또한 앞서 나왔던 PrincipalDetails는 UserDetails 부분에 해당한다. 보통 모델에서 사용하는 유저 클래스가 이 인터페이스를 구현한다. 이 인터페이스에는 스프링 시큐리티에서 해당 유저 모델을 사용하기 위해서 필요한 여러 필드와 메소드(개별 유저의 권한 리턴하기, 유저가 유효한지 확인하는 메소드 등)가 선언되어 있다.
'server-side > spring' 카테고리의 다른 글
| Spring Security 구조 이해해 보기 (0) | 2023.07.11 |
|---|---|
| AWS RDS: 스프링 서버와 AWS DB 연결하기 (0) | 2023.06.30 |
| Spring Security Tutorial: Basic Authentication, JWT Authentication (0) | 2023.06.25 |
| controller-service-repository (0) | 2023.06.23 |
| JPA-Mysql 연결: Driver 연동 오류, dialect 관련 오류 (0) | 2023.06.22 |