* 해당 포스트는 <파이썬 알고리즘 인터뷰> 공부 후 정리 목적으로 작성되었습니다. *
leetcode 3번 ( https://leetcode.com/problems/longest-substring-without-repeating-characters/ )
풀이 1.
시간 복잡도의 제한이 없다면 for loop를 2번 사용하면 간단히 풀 수 있다.
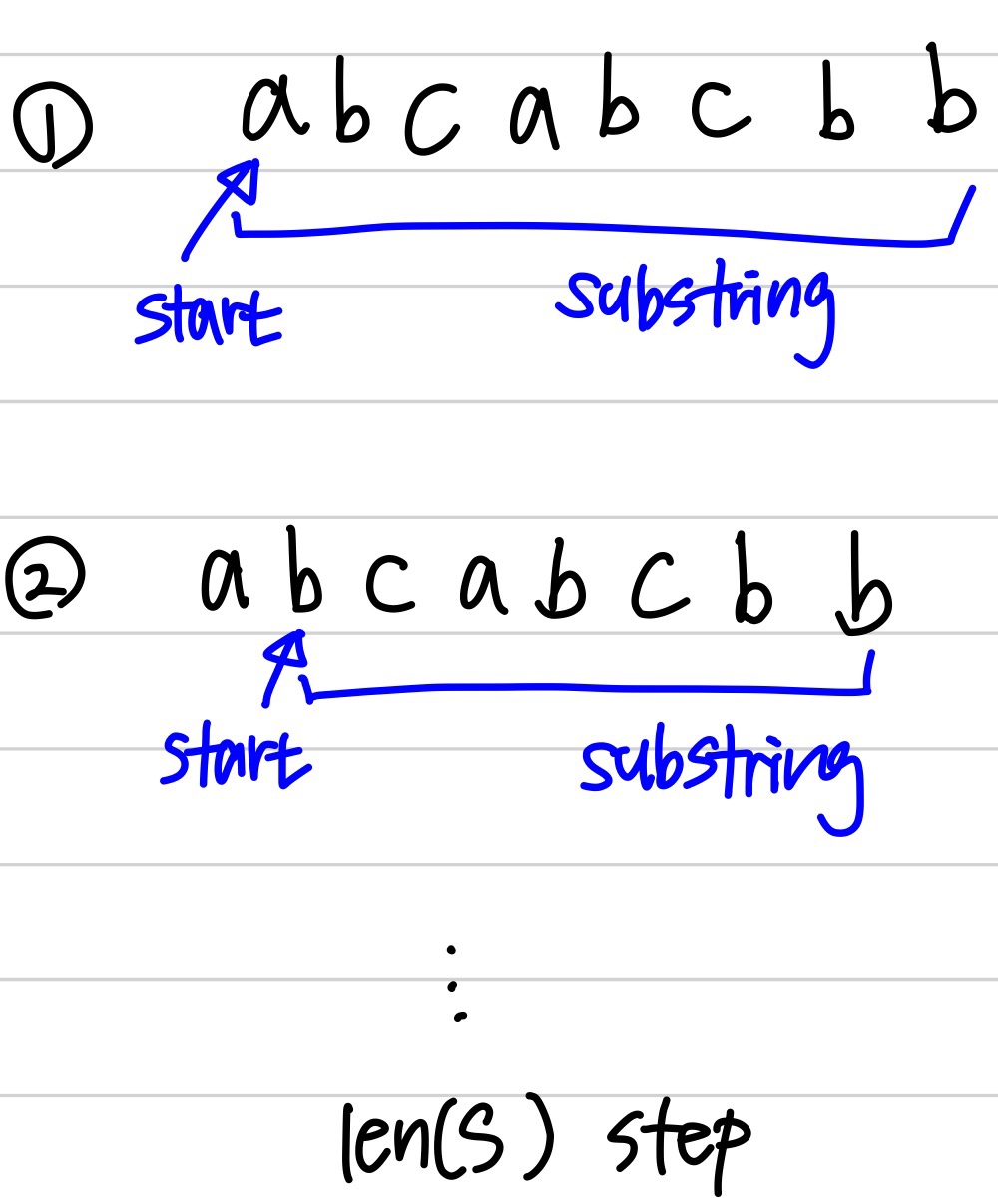
start의 값을 정한 뒤 해당 위치보다 뒤에 있는 문자열들을 전부 돌면서 이전에 나왔던 문자열과 겹치지 않으면 count를 1씩 증가시키고, 겹친다면 for loop에서 탈출한다. 따라서 총 시간 복잡도는 O(n^2)이다.
전체 풀이는 다음과 같다.
class Solution(object):
def lengthOfLongestSubstring(self, s):
maxCount = 0
for i in range(len(s)):
strs = ""
for string in s[i:]:
if string not in strs:
strs += string
else:
break
maxCount = maxCount if maxCount > len(strs) else len(strs)
return maxCount
풀이 2.
교재에서는 더 간단히 풀 수 있는 방법을 제시한다. 바로 for loop를 두 번 도는 대신 투 포인터를 이용해서 for loop를 한 번만 도는 것이다.
이전에 나왔던 문자열인지를 확인하는 작업이 필요한데 여기서는 딕셔너리 변수를 해시맵으로 사용해서 이전에 나온 문자열인지를 확인한다.
포인터 하나(index, string)는 전체 문자열을 돌면서 해당 문자열이 해시맵(used)에 포함되어 있는지를 체크한다. index는 현재 탐색하는 문자열의 위치를, string은 현재 탐색하는 문자열 자체를 값으로 갖는다.
나머지 포인터 하나(start)는 문자열이 시작하는 기준점을 가리킨다.
또한 maxCount 변수도 선언해서 최대값을 계속 업데이트 할 수 있도록 한다.
maxCount = max(maxCount, other_value)
해시맵 used는 문자열을 key로, 해당 문자열의 위치를 value로 갖는다. 문자열을 순회하다가 이전에 있던 문자열이 다시 등장하면 값을 수정한다.
used[string] = index예를 들어서 'a'라는 문자가 1번째 인덱스(앞에서 두 번째)에 있는 경우는 다음과 같다.
만약 index 포인터가 가리키는 문자열(string)의 값이 이미 used에 포함되어 있고, 문자열의 위치 값도 start 포인터 값보다 크다면 해당 문자열은 중복된 문자열이다.
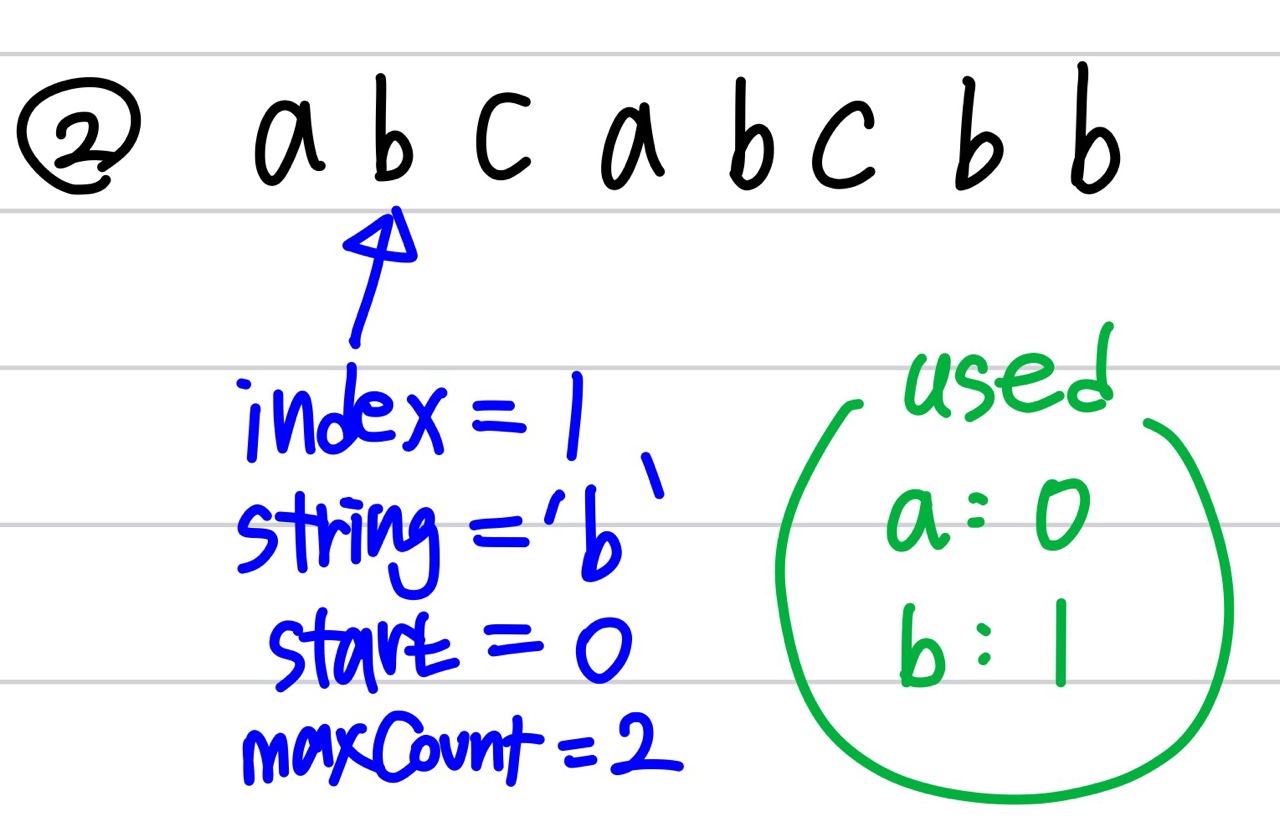
예를 들어서 "abcabcbb" 를 탐색한다고 가정하자.
현재 start(문자열이 시작하는 기준점) 값은 2라고 두면, 'c'부터 문자열이 시작한다고 보면 된다.
그리고 index(순회하는 문자열의 기준점) 값은 5라고 두자. 그러면 index는 두 번째 'c'를 가리키고 있다. 이때 해당 문자열의 위치 값은 5로, start 포인터 값인 2보다 크다. 즉 첫 번째 c를 시작점으로 두고 탐색하고 있는데 두 번째 c가 나온 것이므로 중복 문자열이 나온 것이다.
그럴 땐 start 포인터의 값을 현재 탐색하고 있는 문자열의 위치 + 1로 바꿔 준다.
start = used[string] + 1
만약 아니라면 count 변수의 값을 비교해서 1 증가시킨다.



4번째 경우도 마찬가지로, 첫 번째 'a'에서부터 탐색을 하고 있는데 두 번째 'a'가 등장했으므로 중복 문자열이 나타난 상황이다. 이 경우 used[a]의 값도 새로 변경되고, 0이었던 start 값도 3으로 바꿔 준다.
'알고리즘' 카테고리의 다른 글
| ch12-1(leetcode 200). 섬의 개수 (1) | 2023.01.14 |
|---|---|
| ch11-4(leetcode 347). 상위 K 빈도 요소 (0) | 2023.01.14 |
| ch11-2(leetcode 771). 보석과 돌 (0) | 2023.01.13 |
| ch11-1(leetcode 706). 해시맵 디자인 (0) | 2023.01.13 |
| ch10-2(leetcode 23). k개 정렬 리스트 병합 (0) | 2023.01.12 |



