✅ 오늘 배운 것
오늘 오후까지도 ECS 배포 이슈가 이어지고 있다. 어제 fargate 옵션을 통해 서버를 띄우는 데까지는 성공했다. 장고 서버가 무사히 시작했다는 로그도 보았다. 이 이후에 다른 문제가 있었다.

1. 어딘가에서 잘 실행되고 있는 이 서버에 어떤 엔드포인트로 접속해야 하는지 모르는 문제
2. 마이그레이션 명령어(python manage.py migrate)를 실행하지 않고 바로 실행시켰기 때문에, 분명 RDS에 마이그레이션이 적용되지 않았을 것이다...
-> 이렇게 생각했었는데, 사실 이미 우리 서비스는 원격 RDS를 사용하고 있다. 그렇다는 것은 이미 로컬에서 RDS 연결 테스트를 할 때 명령어로 마이그레이션을 실행해 주었으니, 사실상 이 문제에 대해서는 걱정하지 않아도 되겠다.
어쨌든 1번 문제는 아직 남아있다. 게다가 방금 또 다른 문제 상황을 알게 되었다. 분명히 어제 밤까지는 서비스 내부의 태스크 로그에서 python manage.py runserver 명령어가 잘 실행된 로그를 확인했었다. 그런데 오늘 다시 확인해 보니 실행 중인 태스크가 없는 거였다..!
어제의 경험을 바탕으로 CloudFormation 서비스에 들어가 로그를 살펴보니, ECS에서 failure가 났다는 로그가 남아있었다.
상세 사유를 확인해 보니, fargate 인스턴스에서 ECS 서비스를 생성하는 데 실패했다고 나온 것 같았다. 무슨 문제일지는 더 살펴봐야 알 것 같다.
아무래도 기존에 'ECR ECS'로 검색하면서 나온 여러 블로그와 영상들 중, EC2가 아니라 fargate 옵션이라서 보지 않았던 자료들을 다시 참고해야 할 것 같다.
fargate로 서버 띄워서 접속했다!!!
위의 상황에서 문제가 없는지(로드밸런서 구성은 잘 되었는지, 퍼블릭 서브넷에는 잘 연결되어있는지 기타등등)를 한번 더 점검하고 ECS 클러스터 서비스를 업데이트했다.
역시나 위에처럼 서버는 또 내가 모르는 어딘가에서 잘 실행되는 것처럼 보였다. 사용한 로드밸런서의 퍼블릭 DNS에서도 접속이 안 되고, 태스크의 ENI에 나오는 퍼블릭 주소로도 접속이 안 되길래 도대체 뭐지 싶었다. (여기까지는 어제랑 똑같은 상황이다)
GPT에게 ENI와 로드밸런서의 퍼블릭 주소는 멀쩡한데 접속이 안 된다고 물어보니 보안그룹 설정을 확인해보라고 했고, ECS 태스크의 ENI에서 사용하고 있는 보안그룹 설정을 보니 Anywhere IPv4 설정이 안 되어있는 게 아닌가. 사실 이것도 안드로이드 엡에서 접속하는거면 분명 특정 도메인이나 IP나 프로토콜 접속만을 허용해야 하는 무언가의 룰이 있을 텐데... 일단 이것은 개발서버이니 전부 열어두었다.
그랬더니 이렇게 잘 접속되었다.
로그도 잘 찍히고 있나 싶어서 ECS>태스크>로그를 확인해보았다.
Not Found는 기본 URI에 매핑된 API가 없어서 그런 것이고, 404 response를 리턴하는 이유는 왜인지 모르겠다.
암튼 급한 불은 껐다.
이제 이어서 해야 할 일은 github action으로 이 모든 과정을 자동화하는 yaml 파일을 만들고, 그 과정을 통해 컨테이너가 무사히 ECR>ECS까지 잘 등록되는지를 확인하는 것이다.
평화와 성공의 기쁨도 잠시, 또 Timeout이 났다.
GPT에게 질문해서 오류를 파악해 보았다.

GPT가 제시한 방안은 다음과 같았다.
1. Fargate의 태스크가 중지되었을 수 있으니 이벤트 로그를 확인해라.
2. 로드밸런서의 헬스 체크 설정에 문제가 있는지 확인해라.
3. 리소스 부족 때문에 태스크가 중지된 건 아닌지 확인해라.
4. 애플리케이션 자체의 오류일 수도 있다.
5. 보안그룹이나 네트워크 ACL 같은 네트워크 설정에 문제가 있을 수 있다.
1번의 경우 이벤트를 확인하니 에러가 났다는 로그가 있었다.
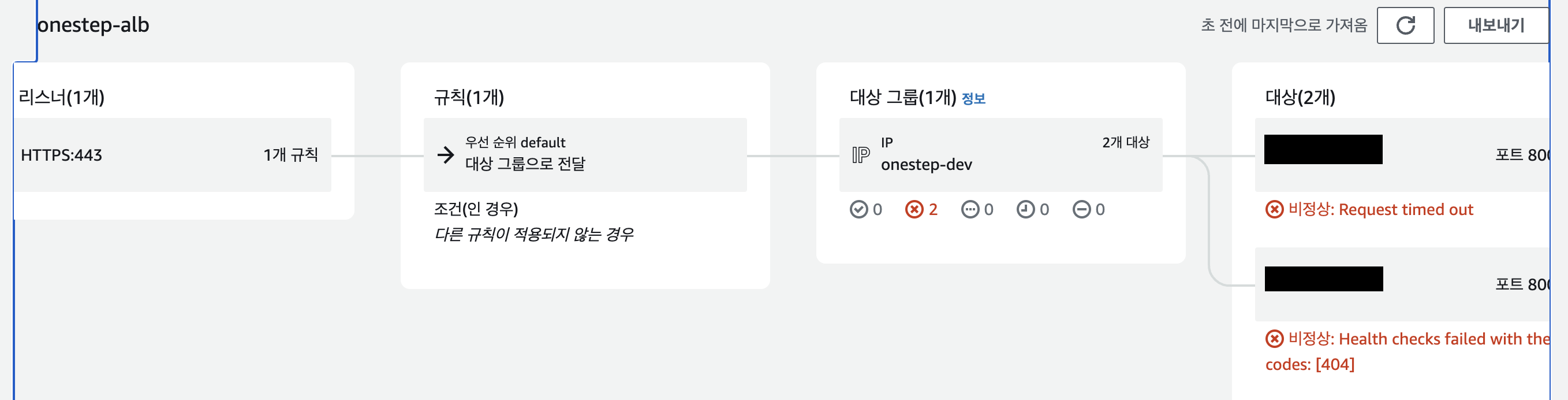
2번의 경우 헬스 체크 설정에 문제가 있는 게 맞았다. 사용하고 있는 로드밸런서(onestep_alb) 설정에 들어가니, 1개의 인스턴스에서는 요청이 타임아웃 되었고, 다른 하나의 인스턴스에서는 헬스체크가 fail 되었다.
3번의 경우 CPU 사용량 등의 리소스 그래프가 확 튀는 모양은 없었으므로 이것은 아닌 것 같았다.
4번의 경우 현재 접속한 것은 swagger API 뿐이고 별다른 오류 로그가 없었으므로 아닌 것 같다.
5번의 경우 그게 원인이었다면 5분 뒤에 접속이 끊길 리 없으니 가능성이 낮다.
오류의 원인이 1-2번이라면 오류가 설명이 된다.
즉 로드밸런서의 헬스체크가 fail로 간주되기 전에 계속해서 시도를 하던 동안에는 서버 접속이 잘 되었는데, 로드밸런서의 헬스체크 기준이 잘못된 것 같았다. 그래서 헬스체크를 fail로 간주하고, 이 태스크가 실패한 것으로 간주되면서 서버에 접속이 안 된다고 추측하고 있다. 그렇다면 로드밸런서의 헬스체크 기준을 바꿔줘야 하겠다.
그래서 바꿔줬다.
정확히는 EC2의 로드밸런서에서 사용 중인 로드밸런서를 클릭하고, 이 로드밸런서가 어떤 대상 그룹으로 요청을 보내주는지를 확인했다.
나의 경우 onestep_alb라는 로드밸런서가 onestep_dev라는 대상 그룹으로 요청을 보내준다.
그런데 onestep_dev 대상그룹의 헬스 체크 기준을 보니 기본 URI(/)로 요청을 보내서 200을 받는 것이 헬스체크의 기준으로 되어있었다. 그런데 어플리케이션 서버의 경우 / 에는 맵핑된 URI가 없었기 때문에 404 에러가 나서 헬스체크에 실패했던 거였다. 그래서 이 URI를 다시 /swagger(모든 API 명세를 볼 수 있는 URI로 상태코드 200을 리턴한다)로 바꿔주었다. 만약 이게 문제였다면 이제는 성공할 것이고, 아니면 또 다른 원인을 찾아야 하겠다.
일단 다시 서비스를 업데이트 하니 서버가 또 잘 뜨긴 한다. 이제 몇 분 뒤에 헬스체크가 다 되었을 시점에 다시 결과를 보면 되겠다.
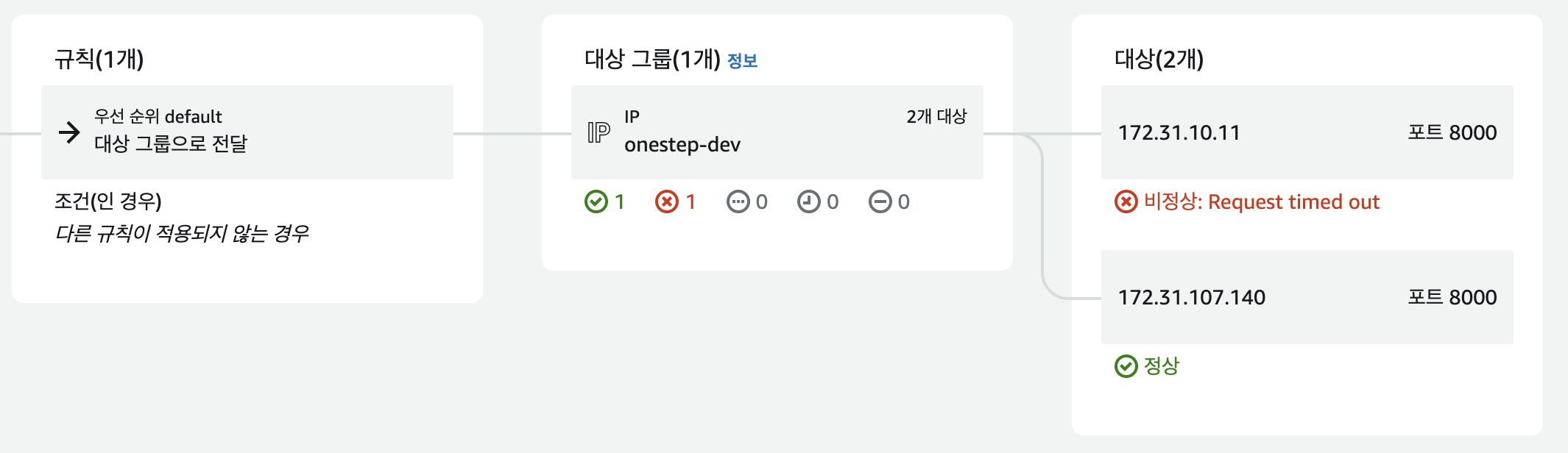
헬스체크 규칙을 바꾸니 10분이 넘어가도 서버가 살아있다! 원인이 이것 때문이었던 것 같다. 그런데 나머지 1개의 인스턴스는 왜 timeout이 뜨는지는 잘 모르겠다.
로드밸런서가 계속해서 /swagger를 호출하면서 헬스체크를 계속하는 이유는 뭘까? 로그를 봤더니 거의 1000개가 있어서 놀랐다.
찾아보니 로드밸런서의 헬스체크 기준에 원인이 있는 것 같았다. 헬스체크 기준은 로드밸런서가 가리키는 대상 그룹(target group)에서 정하는데, 현재 로드밸런서는 10초에 한 번씩 /swagger로 API 요청을 보내고 있었던 것이다. 이러니 부하가 있을 수 밖에! 그래서 10초 대신 maximum인 300초로 바꿔주었다.
그리고 깃허브액션으로 위 작업을 자동화하는 데 성공했다! 여기에는 GPT의 공이 컸지만, 그래도 나도 이 작업을 얼추 이해했기에 내 이해도 돕고 지식도 정리할 겸 남겨본다. yml 파일만 잘 작성되어 있다면 생각보다는 과정은 간단했다.
우선 yml 파일을 GPT의 도움을 받아 작성해준다. 이 yml 파일이 제대로 동작하려면 그 전에 완료되어야 하는 사전 작업들이 있다.
우선은 ECR에 도커 이미지를 올릴 수 있는 레포지토리가 있어야 하고, ECS 클러스터가 생성되어 있어야 하며, 그 클러스터 내에서 실행될 서비스가 생성되어 있어야 하고, ECS 클러스터에서 생성될 작업에 대한 정의(태스크 정의)가 작성되어 있어야 한다. 그리고 여기에 관련된 모든 변수들(ECR 레포지토리의 이름, ECS 클러스터의 이름, ECS 클러스터 안의 서비스의 이름 등)이 github secret에 변수로 등록되어 있어야 한다. 그래야 yml 파일에서 이 값들을 그대로 노출시키지 않고 변수를 통해 할당할 수 있다.
ECS 클러스터에서 생성한 태스크 정의는 변수로 등록할 필요는 없다. 그럼에도 이 태스크 정의가 필요한 이유는 yml 파일을 작성할 때, ECS의 어떤 클러스터의 어떤 서비스에서 어떤 작업(태스크)를 실행할지를 명시해줘야 하는데, 이때 태스크 정의를 생성하면 나오는 JSON 파일이 필요하기 때문이다.
사실 이 JSON 파일도 원래는 프로젝트 루트 디렉토리에 두려고 했었다. 그런데 JSON 파일에서는 .env 파일의 환경변수를 바로바로 등록해주지 못하고 별도로 파이썬 스크립트 파일을 하나 만들어서 그 파일에서 JSON 파일에 환경변수를 집어넣어주는 작업을 해야 한다. 굳이 싶어서 그냥 yml 파일에 그 작업을 넣어주기로 했다.
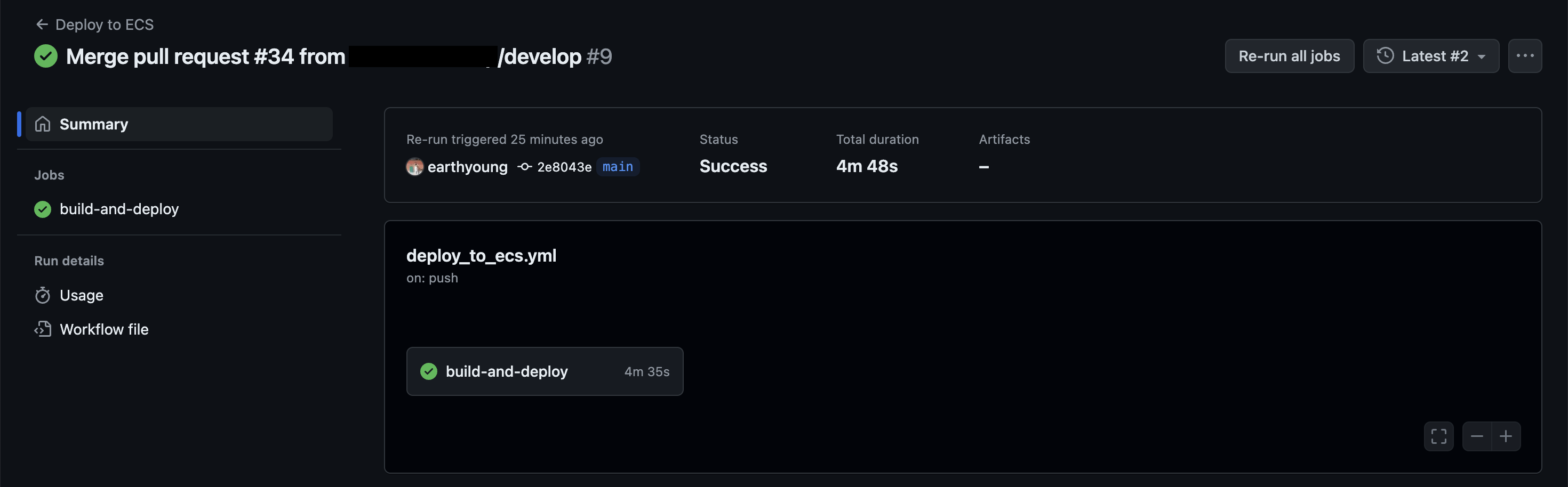
그리고 GPT의 도움을 받아 생성된 yml 파일을 넣어주면, 잘 동작할 수도 있고 오류를 반환할 수도 있다! 나의 경우는 ECS 클러스터의 값이 예전에 생성된 값이었어서 해당 클러스터가 없다는 로그가 떴었다. 이처럼 깃허브 액션의 로그를 잘 보고, 알아서 잘 딱 깔끔하고 센스있게 GPT의 도움을 받아 고쳐주면 머지않아 이런 감동적인 화면을 볼 수 있다.
✅ 궁금한 점
1. ENI는 또 어떤 녀석이며 왜 필요할까
2. 로드밸런서의 DNS 주소와, ECS 태스크의 ENI에 나오는 퍼블릭 주소는 각각 어떤 개념이며 무엇이 어떻게 다른가?
3. 네트워크 ACL은 어떤 녀석인가
4. 로드밸런서에서 헬스체크가 fail이 나면 어떤 일이 발생하나? 설마 태스크의 실패로 간주되어 서비스가 종료되나?
5. 로드밸런서에서 대상그룹으로 요청을 보내준다(포워딩인 듯)는 개념이 어떤 의미일까? 이 개념이나 원리가 잘 이해가 안 된다.
참고한 블로그
https://velog.io/@eunocode/%EC%A1%B0%EA%B0%81%EC%A1%B0%EA%B0%81-json-.env
'개발 일기장 > SWM Onestep' 카테고리의 다른 글
| 20240731 TIL (0) | 2024.07.31 |
|---|---|
| 20240730 TIL: RN에서 UI Kitten으로 모달에서 캘린더 띄우기 (0) | 2024.07.30 |
| 20240728 TIL (2) | 2024.07.28 |
| 20240727 TIL: ECR ECS 적용기 (0) | 2024.07.27 |
| 20240726 TIL (0) | 2024.07.26 |


